Often many children's shoes write papers suffer from data acquisition difficulties, and take the path to reptiles;
Many analysts often use reptiles when doing lyrical monitoring or competitive product analysis.
Today, this article will lead the buddies through 12 lines of simple Python code to get a glimpse of the reptile's secret.
Reptile target
This article uses requests + Xpath to crawl the short commentary on the movie "Black Panther" in the Douban movie.
Running the above crawler script, we can witness the miracle
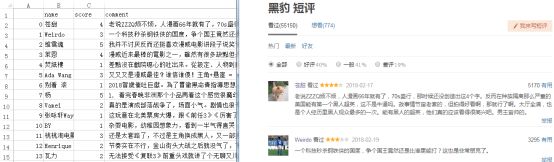
Reptile results are exactly the same as the content of the original web page.
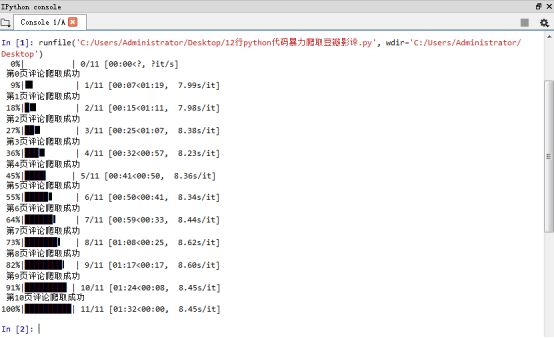
Good interaction through the tqdm module
Tool preparation
Chrome browser (analyze HTTP requests, capture packets)
Install Python 3 and related modules (requests, lxml, pandas, time, random, tqdm) requests: Used to simply request data lxml: parse library faster and more powerful than Beautiful Soup pandas: data processing artifacts time: setting up reptile access intervals to prevent Random: random number generation tool, with time using tqdm: interactive tools, showing the progress of the program
The basic steps
Network request analysis
Webpage content resolution
Data read storage
Involving knowledge points
Crawler protocol
Http request analysis
Requests
Xpath syntax
Python basic syntax
Pandas data processing
Crawler protocol
The crawler protocol is the robots.txt file in the root directory of the web site. It is used to tell reptiles which ones they can take and which can't be stolen. Crawl-delay informs the website of the expected interval of visits. (In order to take the data from the other side of the server's classmates, and to take data, this article sets the reptile access interval to a random number of 6-9 seconds.)
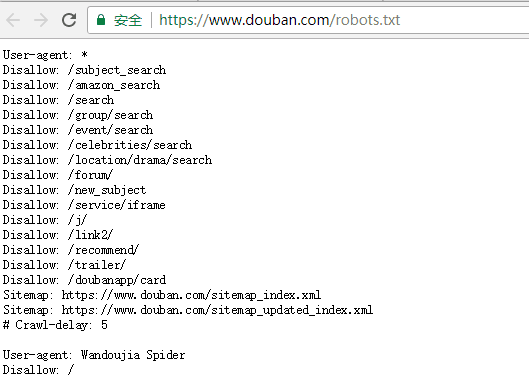
Reppet Web Site Crawler Agreement
HTTP request analysis
Use the chrome browser to access the "Panther" short comment page https://movie.douban.com/subject/6390825/comments?sort=new_score&status=P, press F12, enter the network panel to analyze the network request, refresh the page again Get the request, use the chrome browser to filter the request, analyze, find the Ta
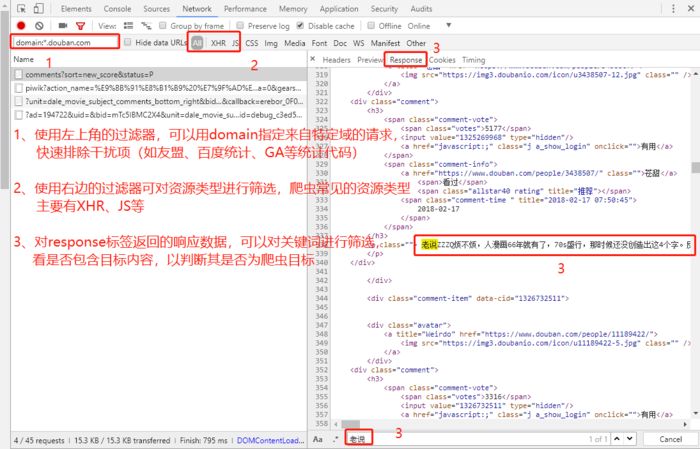
The watercress comment page request analysis
Through the request analysis, we found the target url is 'https://movie.douban.com/subject/6390825/comments?start=0&limit=20&sort=new_score&status=P&percent_type=', and each page, the parameter start will be upward Increased by 20 (through multiple page turning attempts, we found that after page 11 we need to log in to view, and the login status shows only the first 500 short comments. As a simple demo, this article only crawls the first 11 pages)
Requests
Send a get request through the requests module, use the content method to get byte data, and re-encode it with utf-8; then add an interaction to determine whether the resource was successfully acquired (status code is 200), and output the acquisition status.
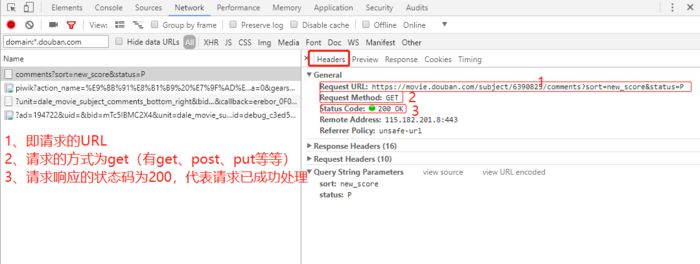
Request details analysis
(In addition to the content, there is a text method, which returns a unicode character set, directly using the text method encountered in Chinese is garbled)
XPath parsing
After obtaining the data, the content of the web page needs to be parsed. Commonly used tools include regular expressions, Beautiful Soup, Xpath, and the like; among them, XPath is fast and convenient. Here we have obtained the data of the first 220 short review user names, short ratings, and short comment content through the Xpath resolution resource. (You can copy Xpath directly with the power of chrome, learning Xpath syntax http://)
data processing
After getting the data, we construct the dictionary through the list, then construct the dataframe through the dictionary, and output the data as a csv file through the pandas module.
Conclusion and Easter Eggs
In this case, through the solutions of requests+Xpath, we successfully crawled some of the watercress comments on the movie “Black Panther†to lay the foundation for text analysis or other data mining work. This article as a demo only shows a simple crawling process, and more eggs such as request headers, request body information retrieval, cookies, simulated logins, distributed crawlers, etc., please pay attention to later article updates.
Crystal Clear Back Sticker,Phone Sticker,Mobile Phone Back Skin,Crystal Clear Phone Skin
Shenzhen Jianjiantong Technology Co., Ltd. , https://www.jjthydrogelmachine.com