One of the key values ​​of an operating system such as Linux is to provide an abstract interface for a specific device. Although various other abstract models such as "network devices" and "bitmap displays" have appeared, the original "character device" and "block device" device types are still prominent. In recent years, persistent memory is hot, [unlike the non-volatile storage NVRAM concept, persistent memory emphasizes reading and writing persistent storage in memory access mode, completely different from the block device layer], but for a long time in the future Inside, the block device interface is still the protagonist of persistent storage. The purpose of these two articles is to uncover the veil of the protagonist.
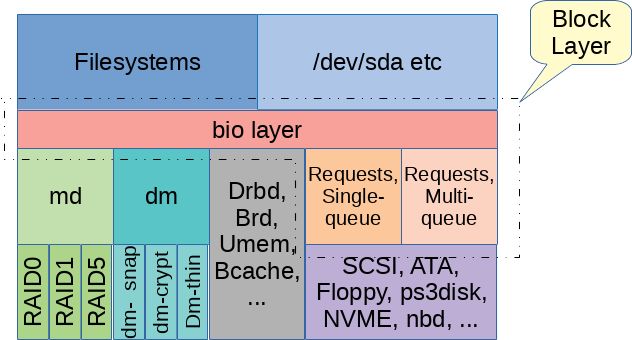
The term "block layer" is often referred to as a very important part of the Linux kernel - this part implements the interface between the application and the file system to access the storage device. What code is the block layer composed of? There is no accurate answer to this question. One of the simplest answers is all the source code in the "block" subdirectory. These codes can be viewed as two layers, and the two layers are closely related but distinctly different. I know that these two sub-levels are not yet recognized, so it is called "bio layer" and "request layer" here. This article will take us first to understand the "bio layer" and discuss the "request layer" in the next article.
Above the block
Before digging the bio layer, it is necessary to understand the background and look at the world above the block. Here "above" means close to the top of the user, away from the bottom, including all code that uses the block service.
Usually, we can access the block device through the block device file in the /dev directory, where the block device file is mapped to an inode with the S_IFBLK flag. These inodes are a bit like symbolic links and do not themselves represent a block device, but rather a pointer to a block device. More specifically, the i_bdev field of the inode structure points to a struct block_device object that represents the target device. The struct block_device contains a field pointing to the second inode: block_device->bd_inode, this inode will work in block device IO, and the inode in the /dev directory is just a pointer.
The main role of the second inode (implementation code is mainly in fs/block_dev.c, fs/buffer.c, etc.) is to provide the page cache. If the device file is opened without the O_DIRECT flag, the page cache associated with the inode is used to buffer the pre-read data, or to cache the write data until the writeback process flushes the dirty page to the block device. If O_DIRECT is used, reads and writes bypass the page cache and send requests directly to the block device. Similarly, when a block device is formatted and mounted as a file system, the read and write operations usually work directly on the block device [The author is wrong? ], although some file systems (especially the ext* family) have access to the same page cache (formerly called buffer cache) to manage some file system data.
Open() Another flag associated with block devices is O_EXCL. Block devices have a simple advisory-locking model, and each block device can have at most one "holder". When a block device is activated, [activation refers to the process of driving a block device, including adding objects representing the block device to the kernel, registering the request queue, etc.], and the blkdev_get() function can be used to specify a "holder" for the block device. [ The prototype of blkdev_get(): int blkdev_get(struct block_device *bdev, fmode_t mode, void *holder), holder can be a super block of a file system, or a mount point, etc.]. Once the block device has a "holder", subsequent attempts to activate the device will fail. Usually when mounting, the file system assigns a "holder" to the block device to ensure that the block device is used interchangeably. When an application attempts to open a block device in O_EXCL mode, the kernel will create a new struct file object and use it as the "holder" of the block device. If the block device is already mounted as a file system, the open operation will fail. . If the open() operation succeeds and has not been closed, the attempt to mount will block. However, if the block device is not opened with O_EXCL, O_EXCL cannot prevent the block device from being opened at the same time. O_EXCL is only convenient for the application to test whether the block device is in use.
Regardless of how the block device is accessed, the primary interface sends a read and write request, or other special request such as a discard operation, and finally receives the processing result. The bio layer is to provide such a service.
Bio layer
The block device in Linux is represented by struct gendisk, which is a generic disk. This structure does not contain too much information, mainly to play the role of the link, the file system, the lower block. Going up, a gendisk object is associated with the block_device object. As we mentioned above, the block_device object is linked to the inode in the /dev directory. If a physical block device contains multiple partitions, that is, there is a partition table, then the gendisk object corresponds to multiple block_device objects. Among them, there is a block_device object representing the entire physical disk gendisk, and other block_device each representing a partition in the gendisk.
Struct bio is an important data structure of the bio layer to represent read and write requests from block_device objects, as well as various other control class requests, and then communicate these requests to the driver layer. A bio object includes information about the target device, the offset in the device address space, the request type (usually read or write), the read and write size, and the memory area used to hold the data. Prior to Linux 4.14, the bio object used block_device to represent the target device. Now the bio object contains a pointer to the gendisk structure and the partition number, which can be set by the bio_set_dev() function. This highlights the core position of the gendisk structure, which is more natural.
Once a bio is constructed, the upper layer code can be submitted to the bio layer for processing by calling generic_make_request() or submit_bio(). [submit_bio() is just a simple wrapper around generic_make_request()]. Usually, the upper code does not wait for the request processing to complete, but instead puts the request on the block device queue and returns. Generic_make_request() can sometimes block a small amount of time, such as waiting for memory allocation, which may be easier to understand. It may have to wait for some requests already processed on the queue to complete, and then make room. If the REQ_NOWAIT flag is set on the bi_opf field, generic_make_request() should not be blocked under any circumstances. Instead, the bio return status should be set to BLK_STS_AGAIN or BLK_STS_NOTSUPP and then returned immediately. As of writing, this feature has not been fully realized.
The interface between the bio layer and the request layer requires the device driver to call blk_queue_make_request() to register a make_request_fn() function, so that generic_make_request() can handle the bio request to submit the block device by calling this function. The make_request_fn() function is responsible for handling the bio request. When the IO request is completed, it calls bio_endio() to set the state of the bi_status field to indicate whether the request was processed successfully, and to call back the bi_end_io function stored in the bio structure.
In addition to the above simple handling of the bio request, the two most interesting features of the bio layer are: avoiding recursion avoidance and queue plugging.
Avoid recursion avoidance
In the storage scheme, "md" [mutiple device] (soft RAID is an instance of md) and "dm" [device mapper] (for multipath and LVM2) are often used, which are often called stacks. The device, organized by multiple block devices in the form of a tree, modifies and passes the bio request along the device tree to the next layer. If a simple implementation of recursion is used, it will take up a lot of kernel stack space when the device tree is very deep. A long time ago (Linux 2.6.22), this problem occurred from time to time, and it was even worse when using a file system that itself was recursively calling a large amount of kernel stack space.
In order to avoid recursion, generic_make_request() will detect it. If recursion is found, the bio request will not be sent to the next device. In this case, generic_make_request() will put the bio request on a queue inside the process (currect->bio_list, a field of struct task_struct), wait until the last bio request is processed, and then submit this layer. request. Since generic_make_request() does not block to wait for the bio processing to complete, it is okay to process the request even after a delay.
Often, this method of avoiding recursion works perfectly, but sometimes deadlocks can occur. The key to understanding how deadlocks occur is our observation of the bio commit method: When recursion occurs, bio has to wait in line for the bio processing that was submitted before. If the waiting bio has not been processed on the current->bio_list queue, it will wait.
The reason that causes bio to wait for each other and create a deadlock is not easy to find. It is usually found in the test, not the analysis code. Take the bio split as an example. When a bio target device has a size or alignment limitation, make_request_fn() may split the bio into two parts and then process them separately. The bio layer provides two functions (bio_split() and bio_chain()), making bio splitting easy, but the bio split needs to allocate space for the second bio structure. Be careful when allocating memory in the block code. Especially when memory is tight, Linux needs to write dirty pages through the block layer when reclaiming memory. If you need to allocate memory when you write it in memory, it will be a hassle. A standard mechanism is to use mempool to reserve some memory for a certain key purpose. Allocating memory from mempool requires waiting for other mempool users to return some memory without waiting for the entire memory reclamation algorithm to complete. When using mempool to allocate bio memory, this wait may cause generic_make_request() to deadlock.
The community has tried several times to provide an easy way to avoid deadlocks. One is the introduction of the "bioset" process, which you can view on your computer with the ps command. The main concern of this mechanism is to solve the deadlock problem described above, assigning a "rescuer" thread to each "mempool" that allocates bio. If bio is not allocated, all bios in currect->bio_list will be taken down and submitted to the corresponding bioset thread for processing. This method is quite complicated, resulting in the creation of many bioset threads, but most of the time it is not useful, just to solve a special deadlock situation, the cost is too high. Usually, deadlocks are related to bio splits, but they don't always have to wait for mempool allocation. [The last sentence, some awkward]
The latest kernels usually don't create bioset threads, but only in a few individual cases. The Linux 4.11 kernel introduces another solution. The changes to generic_make_request() have the advantage of being more generic and less expensive, but they require a bit of a driver. The main requirement is that when a bio split occurs, one of the bios should be submitted directly to generic_make_request() to arrange the most appropriate time processing. Another bio can be processed in any suitable way, so that generic_make_request() has a stronger Control. According to the depth of the bio in the device stack at the time of submission, after sorting the bio, the bio of the lower layer device is always processed first, and then the bio of the higher layer device is processed. This simple strategy avoids all annoying deadlock issues.
Block queue activation (queue plugging)
The cost of a storage device handling a single IO request is usually high, so one way to increase processing efficiency is to aggregate multiple requests and then make a batch commit. For slow devices, there are usually more requests for queues, so there are more opportunities for batch processing. However, for fast devices, or slow devices that are often idle, the chances of doing batch processing are significantly less. To solve this problem, the Linux block layer proposes a mechanism called "plugging". [plugging, that is, plugging the plug, the queue is like a pool, the request is like water, and the plug can be used to store water]
It turns out that plugging is only used when the queue is empty. Before submitting a request to an empty queue, the queue will be "blocked" for a while, so that the request is saved and not submitted to the underlying device for the time being. The bio submitted by the file system will be queued for batch processing. The file system can actively request, or the timer periodically times out to unplug the plug. What we expect is to aggregate a batch of requests within a certain amount of time, and then start processing IOs after a delay, rather than always accumulating a lot of requests. Starting with Linux 2.6.30, there is a new plugging mechanism that changes the object of the savings request from device-oriented to process-oriented. This improvement is very scalable on multiple processors.
When a file system, or a user of another block device, submits a request, it usually adds blk_start_plug() and blk_finish_plug() before and after calling generic_make_request(). Blk_start_plug() initializes a struct blk_plug structure with current->plug pointing to it. This structure contains a list of requests (we'll talk about this in the next article). Because this request list has one for each process, there is no need to lock when adding a request to the list. If the request can be processed more efficiently, make_request_fn() will add bio to this list.
When blk_finish_plug() is called, or when schedule() is called for process switching (for example, waiting for a mutex lock, waiting for memory allocation, etc.), all requests stored in the current->plug list are committed to the underlying device, that is, The process can't take the IO request to go to sleep.
When schedule() is called for process switching, the accumulated bio will be processed in its entirety. This fact means that the delay in bio processing will only occur during the continuous generation of new bio requests. If the process waits to go to sleep, the accumulated bio will be processed immediately. This can avoid the problem of loop waiting. Imagine a process waiting for a bio request to complete processing and go to sleep, but the bio request is still not sent to the underlying device on the plug list.
The main advantage of a process-level plugging mechanism like this is that the most relevant bios are easier to aggregate for batch processing, and the second is to greatly reduce the competition for queue locks. If there is no process level plugging, then every bio request comes with a spinlock or atomic operation. With such a mechanism, each process has a bio list, and when the process bio list is merged into the device queue, only the last lock is enough.
Bio layer and below
In short, the bio layer is not very complicated, it will directly pass the IO request to the corresponding make_request_fn() in the way of the bio structure [specific implementation of blk_queue_bio() with common block layer, dm_make_request() of DM device, md_make_request of MD device ()]. The bio layer implements a variety of common functions to help the device driver layer handle the bio split, scheduling the sub-bios [will not translate this, meaning should be how to arrange the split bio after processing], "plugging" request and so on. The bio layer also does some simple operations, such as updating the count of pgpgin and pgpgout in /proc/vmstat, and then handing over most of the IO request to the next layer of processing [request layer].
Sometimes, the next layer of the bio layer is the final driver, such as DRBD (The Distributed Replicated Block Device) or BRD (a RAM based block device). The more common layer is MD and DM to provide such virtual devices. middle layer. The indispensable layer is the rest of the bio layer, which I call the "request layer", which will be the topic we discuss in the next article.
The advantage of entertainment tablet lies in having a powerful chip and excellent hardware. If you want to play various online videos on the tablet and run various software smoothly, the performance of the hardware is an absolute prerequisite. In addition, a high-speed and stable WIFI module is also required, which must be compatible with multiple 802.11 B/G/N protocols at the same time, so that the webpage can be loaded instantly when the webpage is opened, and the online video can be played smoothly. So hardware is the premise and foundation, without good performance everything else is empty talk.
In addition to having a good CPU as a prerequisite, it is equally important to carry a professional video player. A professional video player must perform equally well both online and offline.
Entertainment Tablet,High capacity battery Tablet,WIFI Tablet
Jingjiang Gisen Technology Co.,Ltd , https://www.jsgisentec.com