Lei Fengwang Note: This article author Xu Tie, Master of Physics, Paris, France, Israel Institute of Technology (Israel 85% of the cradle of scientific and technological entrepreneurial talent, computer science world-renowned) Doctor of Computational Neuroscience, founder of Cruiser Technology Co., Ltd. One year at the University Non-linear Science Center.
The topic of Alpha Dog, which has been widely discussed for a long time, actually contains profound machine learning wisdom. It is an excellent textbook for learning machine learning and even human decision-making. Machine learning is the key to Alphago's victory. Why it will play a big role, see below.
The best way to understand a science and technology is to find out the core paper. Let's look at how Alpha Dog's core paper interprets this problem. And if you put you in such a position, how would you design this game ?
If you understand the history of chess and card games and the history of computer games with them, you will be very clear about the routines of old-school programmers, and you will understand that the easiest way to solve this type of problem is to exhaustively use the law, such as the historic eight-queen problem. You need to Place eight queens on the chess board so that they are not located on each other's vertical line, horizontal line or diagonal line. You only need to follow a certain method to make a loop, and traverse from the first row to the next row. When you encounter a situation that cannot be opened, go back to the last step and finally re-swap. Finally, you can always find a combination without problems.

Picture: Eight Queens, Exhausting and knowing that it is enough to retreat, eight women are not difficult to arrange
A slight improvement in similar methods can solve the problem of chess, but it is difficult to solve the problem of chess. Why? Because we all know, the dimension of Go is too large. Each time there are several hundred (1919), it is possible to imagine that if a game of chess is to be won after a few hundred steps, how many possibilities do you have? It is difficult to solve it by any algorithm that is detached from the exhaustive method.
Here is how to effectively reduce the search space, the core issue . This is why a problem of going to a go requires the use of machine learning, because machine learning lets you infer all other possibilities through finite data (similar to an interpolation process).
Let the machine do this beforehand to see how people do it. In fact, the core of the decision is how to reduce the search space. Although life may be limited to a certain extent, most of you may not even consider it, such as going to North Korea to immigrate or selling bananas to Bangladesh. We humans use stupid, clever, reasonable and unreasonable words to describe the advantages and disadvantages of various choices, and the brain automatically shields most of the unreasonable explanations. How did you get these answers? The first one is how to calculate the result of each behavior through the year-round trial and error. The other is reading books and talking with masters to learn their experiences directly .
The converse is the principle of machine learning, first of all trial and error learning, or the method of adjusting the behavioral strategy based on the outcome of a certain behavior. We usually call this reinforcement learning .
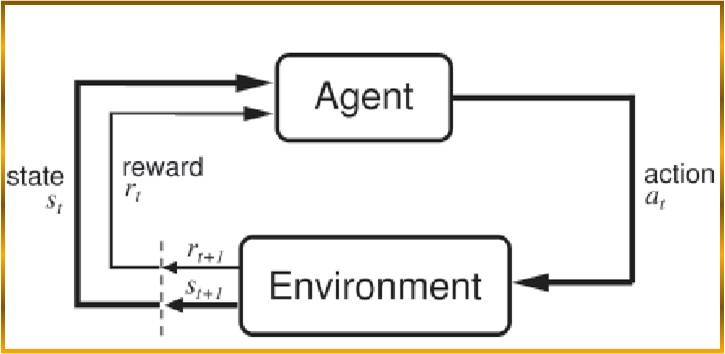
Reinforcement learning is usually implemented by using the above block diagram. That is, the agent will adjust the feedback system based on the feedback given by the environment to ultimately maximize the benefits. The difficulty is that the behavior of the agent usually changes the environment, while the environment affects the behavioral strategy.
Specific to go, the core of this strategy is based on the characteristics of Go:
1. The information on both sides is fully known at each step
2. The strategy for each step need only consider the status of this step
This allows machine learning to solve this problem with a very fiercely simplified framework, the Markov decision process . That is, we use a discrete time series to describe the state s, and another discrete time series to express the behavior a. The two time series have a deep coupling relationship. The next moment's state s(t+1) depends on the moment's behavior. The a(t) and the state s(t) ultimately determine the relationship between the next moment's behavior a(t+1), ie, the strategy P(a(t)|s(t)). Since it is a Markov chain, So the strategy at each moment is only related to the current state s(t).
All kinds of chess are the most obvious horse chains. Because of the uncertainty in the future, the strategy itself is also a form of a probability distribution function. In the end, we want to optimize the maximum R(s) returned by taking P(s|a). Markov's decision-making process is a very favorable way to solve the problem of uncertainty in the future state and behavior of Marathon.
A simple and practical rough algorithm to solve the Markov decision process is called Monte Carlo Tree Search (MCTS).
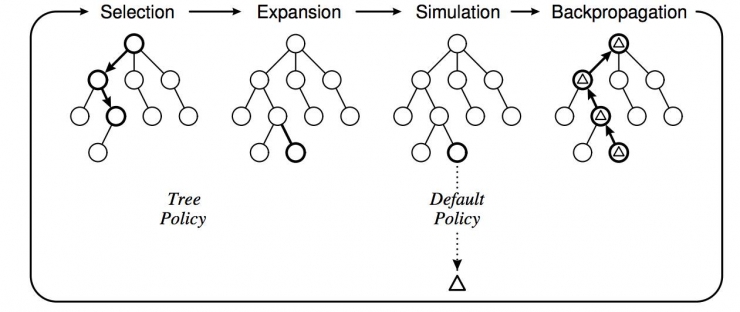
Figure: Monte Carlo Tree with its four steps, selection, expansion, simulated valuations and results back, corresponding to a classic reinforcement learning framework
Speaking of Monte Carlo, this is the famous method of random sampling. In the so-called tree, we must think of a decision tree. The nodes of the tree are momentary states. The branches represent a decision. The Monte Carlo tree here is the process of generating the entire decision tree using a random sampling method.
Suppose the computer is in the state of s(t), then you just throw a sieve and go one step, then the computer simulation opponent also throws a sieve to take a random step, so go down and there will always be a winner, this time you review The history of the victory and defeat of the person’s trajectory, the winning approach adds one point to each state (branch) on the entire decision tree, and the lost step is reduced by one point at each step. This score will affect the The probability of one sampling will make it easier to obtain the more easily won steps. After reciprocating computers and computers indefinitely, they will choose strategies that are particularly easy to win. This process is similar to the evolutionary selection algorithm. It is to make those who have the advantage to have higher progeny probabilities of breeding, so as to finally win, reflecting the game between biology and the environment .
Note: Here is a small question. Markov's decision-making process is very powerful. But in the real decision-making, which university do you want to go to school, which stock do you want to choose, all the strategic choices are difficult to look at just now, this framework can also How much?
Reinforcement learning represented by the Monte Carlo tree has the potential to reduce the search space by a fraction of the likelihood that Go moves in this way, making the computer reach the level of a senior amateur player, and if we want to further reduce the search space. What do we need to do? At this point we can go back and think of an important way that humans mentioned in the search space reduction is to learn masters' experience. Yes, yes, backlogs, see more, there is a sharp intuition out A coup. Translating it into a mathematical language means that by looking at the scores of the game, you can obtain a correspondence between any strategy and the final equity in a certain situation, even if you have never seen it before.
Note: Be careful here. We often feel that the intuition seems to be an alienation from the sky. The opposite is true. Intuition is the most need to learn.
Let the machine do the regression algorithm with supervised learning. You need to extract the characteristics of the game and calculate the probability P(a(t)|s(t)) for each occurrence. However, the characteristics of the chess game are too complicated. If you come to a linear regression or KNN, you will definitely die. At this time our deep learning began to come in handy. It can spontaneously learn the characterization of things.

Figure, training network connection through gradient backhaul
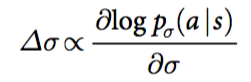
The goal of machine learning training is to maximize the probability of data being observed. The so-called Maximum Likelihood is the adjustment of network connection parameters for neural networks.
The process of deep learning is just like we see more than one thing. Starting spontaneously has the ability to perform inverse actions. It can be called adding intuition to strategic choices. At this time, you can grasp infinity through limited experience. During the training process, Alphago kept on predicting what the experts might do based on the current situation. After training with 30 million sets of data, deep learning can achieve a prediction rate of 55.7%. This probability indicates that human intentions are also It's not hard to be guessed, and it's also why people would say that playing with Alphago is like playing against countless masters. Of course, this is not the end of training. The neural network here only traces the action of the master. Afterwards, we must let him win. It is like understanding and optimizing the master's tricks in practice. This is the second step of the training. Using the reinforcement learning method to train the network connection coefficient, the specific method is to let the existing strategy network and randomly select a previous strategy network to perform left and right beats, and then pass the outcome of the outcome to each step strategy for gradient training. . After this process, the strategy network can be seconds away from some mid-level fan-level algorithms and describe the status of various masters before.
 Figure: Thinking of the strategy network, calculating the probability of each occurrence
Figure: Thinking of the strategy network, calculating the probability of each occurrence
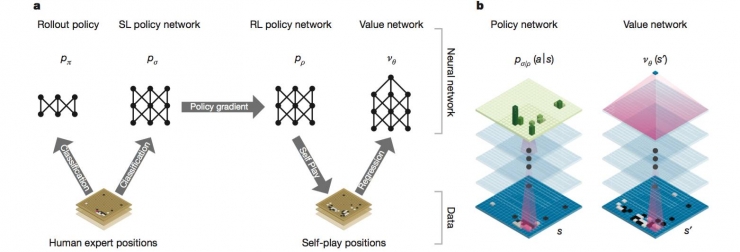
The final step in training is to evaluate the network and talk about what the valuation network is doing here. First, under a reinforcement learning framework, you need to know the deterministic rewards for each behavior. The difficulty lies in the fact that you can only have a definite return when you go through chess. It is daunting to think about the infinite possibilities in the Go step and the possible number of steps to get the result. The role of the deep learning algorithm is precisely to estimate the profit expectations of this step without having to go through the process. Using an in-depth network through the framework of reinforcement learning. The essence of the valuation network is to establish links between existing behaviors and long-term benefits. Some people call it a trend and a big picture. To train such a network to calculate returns, look down.
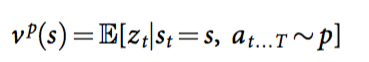
Formula: The problem to be solved by the training, and the expectation of taking the final profit of the strategy p under the state S

Figure: A rendering of the valuation network. Numbers are returns
Then the question arises. How do Monte Carlo trees and deep learning combine seamlessly? This is where the entire Alphago design is most ingenious: First, you should remember the MCTS framework. First MCTS can be disassembled into 4 steps: the first selection, the sampling option in the existing options (experienced), the second Expansion, to go to a situation that has never been experienced before, to explore new behavior, that is, generate new branches, third Evaluation, get new behavior returns, fourth, return, pass the results of the reward back to the strategy. The results of deep learning can be perfectly embedded in the steps of Monte Carlo search. First of all, in the expansion step, we do not have to randomly generate an unprecedented state from scratch, but use a strategy network based on previous experience training directly. Generate new states, massively reducing useless searches. Then, in the Evaluation step, we don't need to run the entire game, but we can directly calculate the possible long-term return of this new position through the results of deep learning (here, the great role of the valuation network, the so-called step-by-step see After a long period of time, the calculated return will be combined with the results of real practice when the final game is completed.
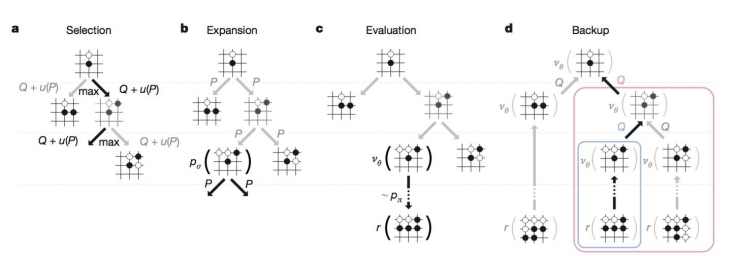
Figure: Deep Learning How to Embed Monte Carlo Tree Search
Unlike deep blue, which beats chess masters, machine learning plays a huge role in Alphago's case, because Alphago's strategy and intelligence are mainly evolved by constantly looking at the game's chess and left and right hands. This rule is very complicated for Go. It is impossible to design a set of winning rules, and only the evolutionary and self-improvement ideas of machine learning (reinforcing learning) are the ultimate victors. It is also why Alphago's technology is very inspiring for other artificial intelligence.
From the above analysis of the above, in fact, training Alphago's algorithm ideas is not very complicated, summed up in one sentence, is on the giant's shoulder quickly try wrong. This is also the best way to make a variety of life decisions. You said that you want to live a unique life without simulating anybody. You think that it is a silly X who crashes into the south wall. You said that you must watch the best elite follow and you may repeat the life of others in your life. The person of the Bull X, apparently standing on the shoulders of the giants, traces the 30 million elite's footwork and sums up the rules in depth, and then changes his action patterns. However, we humans do not have so many hours to complete the simulation, and there are not so many GPUs for parallel operations. Therefore, what we are actually looking for is an approximate solution with low search cost, that is, a suboptimal solution.
Welcome to follow the follow-up of cruiser machine learning against complex system series--an example of reinforcement learning in grid design
Lei Feng Network (Search "Lei Feng Network" public concern) Note: This article is issued by Xu Tie - Chaos cruiser authorized Lei Feng network, for reprint please contact the micro signal 562763765.
Office Power,Office Atx Power Supply,Office Mute Atx Power,Office Mute Power
Boluo Xurong Electronics Co., Ltd. , https://www.greenleaf-pc.com