1. Preparation
This article is based on the linux 2.6.32-rc7 version of the source code, so please prepare a linux2.6.32-rc7 code. It is recommended to use the following two methods to obtain the source code:
1. Download the source package directly on linux.org.
2. Use git to pull the latest code from linux-next and check out the 2.6.32-rc7 version of the source code using git checkout -b linux-2.6.32-rc7 v2.6.32-rc7.
2. Overview
Although classic RCUs in earlier versions of Linux have excellent performance and scalability for read primitives, write primitives need to determine when a pre-existing read critical region is completed. It is only designed for numbers. Ten CPU system. The implementation of the classic RCU requires that each CPU must acquire a global lock in each elegant cycle, which limits their extensibility. Although in the actual production system, the classic RCU can run on hundreds of CPU systems, even more difficult to use the system to thousands of CPUs, large multi-core systems still need better scalability.
In addition, the classic RCU has a non-optimal dynticks interface, causing the classic RCU to wake every CPU in every elegant cycle, even if these CPUs are in the idle state. We consider a 16-core system where only four CPUs are busy and other CPUs are lightly loaded. Ideally, the remaining 12 CPUs can stay in deep sleep mode to save energy. Unfortunately, if four busy CPUs perform RCU updates frequently, these 12 idle CPUs are periodically woken up, wasting important energy. Therefore, for any optimization of the classic RCU, these sleep state CPUs should be kept asleep.
Both classic RCU and hierarchical RCU implementations have the same semantics and APIs as the classic RCU. However, the original implementation is called "Classic RCU" and the new implementation is called "Classified RCU."
2.1. RCU Foundation Review
In the most basic terms, RCU is a way to wait for a transaction to complete. Of course, there are many other ways to wait for a transaction to complete, including reference counting, read-write locks, events, and so on. One of the big advantages of RCU is that it can wait for 20,000 different events at the same time without having to specifically track each of them, and there is no need to worry about performance degradation, scalability is limited, and there is no need to worry about complex deadlocks and The risk of memory leaks.
In the RCU, the waited event is called "RCU read end critical section." The RCU read-end critical region starts with the rcu_read_lock() primitive and ends with the corresponding rcu_read_unlock() primitive. The RCU read-end critical section can be nested, or it can contain quite a bit of code, as long as the code does not block or sleep (of course, this is for the classic RCU. There is a special sleepable RCU named SRCU which allows Short-term sleep in the SRCU read-end critical region). If you follow these constraints, you can use the RCU to wait for any code fragment to complete.
The RCU achieves this by indirectly determining when other transactions are completed. However, please note that the RCU read-end critical area that begins after a particular grace period can and will inevitably extend the end point of the grace period.
2.2. Summary of Classic RCU Implementation
The key principle of the classic RCU implementation is that the kernel code of the classic RCU read-end critical region does not allow blocking. This means that at any point in time, a particular CPU will only appear to be in a blocked state, an IDLE loop, or after leaving the kernel, we know that all RCU readers have completed critical sections. These states are referred to as "stationary states." When each CPU has experienced at least one standstill, the RCU elegant cycle ends.
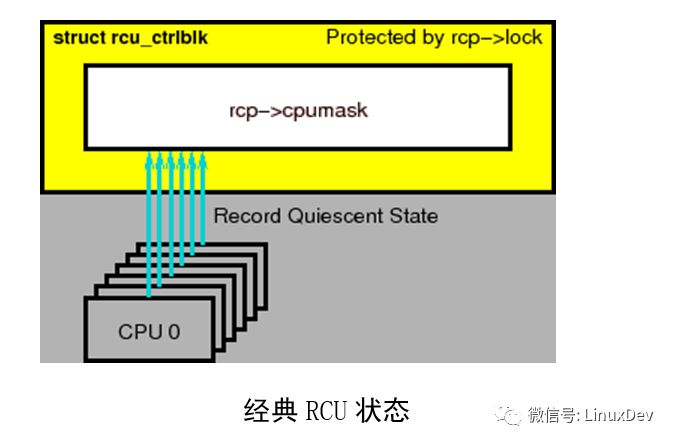
The most important data structure of the classic RCU is rcu_ctrlblk, which contains the -> cpumask field. Each CPU contains one bit in this field, as shown in the above figure. When each elegant cycle starts, the corresponding bit of each CPU is set to 1, and each CPU must clear the corresponding bit when it passes a stationary state. Since multiple CPUs may want to clear their bits at the same time, this will break the ->cpumask field, so a ->lock spinlock is used to protect ->cpumask. Unfortunately, this spin lock encounters a severe race condition when there are more than a few thousand CPUs. What's worse is that in fact all CPUs have to clear their bits, which means that in an elegant cycle, the CPU is not allowed to sleep all the time. This weakens LINUX's ability to save energy.
2.3. Urgent Problems to be Solved by the RCU
The list of issues that the real-time RCU urgently needs to solve is as follows:
1. Delayed destruction. In this way, a grace period of one RCU cannot end until all the pre-existing RCU read-end critical regions have been completed.
2. Reliability, so RCU supports 24x7 operation.
3. Can be called in IRQ handlers.
4. Include memory tags, so that if there are many callbacks, this mechanism will speed up the end of the grace period.
5. Separate memory blocks so that the RCU can operate based on a trusted memory allocator.
6. The synchronization-read reader, which allows normal non-atomic instructions to operate on the local memory of the CPU (or task).
7. Unconditional read-to-write promotion, in the Linux kernel, there are several places that need to be used.
8. Compatible APIs.
9. The requirement to seize the critical section of the RCU reader can be removed.
10. Very low RCU internal lock competition, resulting in great scalability. The RCU must support at least 1,024 CPUs, preferably at least 4,096 CPUs.
11. Energy Saving: The RCU must be able to avoid waking up the low-voltage dynticks-idle CPU, but still be able to determine when the current elegant cycle is over. This is already implemented in real-time RCUs, but it needs to be greatly simplified.
12. The critical section of the RCU reader must allow use in NMI handlers, as in the interrupt handler.
13. RCU must manage non-stop CPU hot plug operations.
14. It must be possible to wait for all pre-registered RCU callbacks to complete, although this is already provided as rcu_barrier().
15. It is worthwhile to detect a CPU that has lost response to help diagnose RCU and dead loop bugs and hardware errors, which can prevent situations where the elegant cycle of the RCU cannot end.
16. Accelerating the elegant cycle of the RCU is worth it, so that the elegant cycle of the RCU can be forced to complete in hundreds of microseconds. However, such operations are expected to have a severe CPU load.
The most urgent first requirement is: scalability. Therefore, it is necessary to reduce the internal lock of the RCU.
2.4. Towards an Extensible RCU Implementation
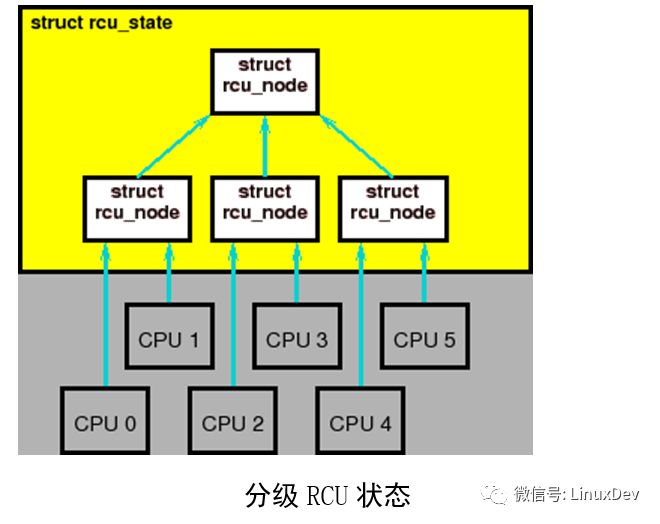
An effective way to reduce lock contention is to create a hierarchy, as shown in the previous figure. Here, each of the four rcu_node structures has its own lock, so that only CPU 0 and 1 will get the lock for the leftmost rcu_node, CPU 2 and 3 will get the lock for the middle rcu_node, and CPUs 4 and 5 will get The rcu_node lock on the right. During any grace period, only one CPU node will access the rcu_node on the layer above the rcu_node structure. In other words, in the above figure, each pair of CPUs (they are in the same CPU node), the last CPU recording the static state will access the rcu_node of the upper layer.
The end result of this is to reduce the lock competition. In the classic RCU, six CPUs compete for the same global lock in each grace period. In the above figure, only three nodes compete for the top-level rcu_node lock (by 50%).
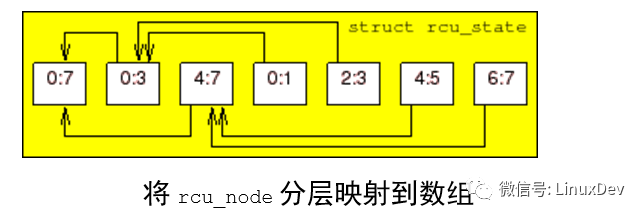
The rcu_node structure tree is embedded in a linear array of rcu_state structures. The root of the tree is node 0, as shown above. It is an 8-CPU, three-tier hierarchical system. Each arrow links an rcu_node structure to its parent node, which corresponds to the ->parent field of the rcu_node structure. Each rcu_node indicates the range of CPU it covers, so that the root node covers all CPUs. Each secondary node covers half of the CPU. Each leaf node covers two CPUs. This array is statically allocated at compile time based on the value of NR_CPUS.
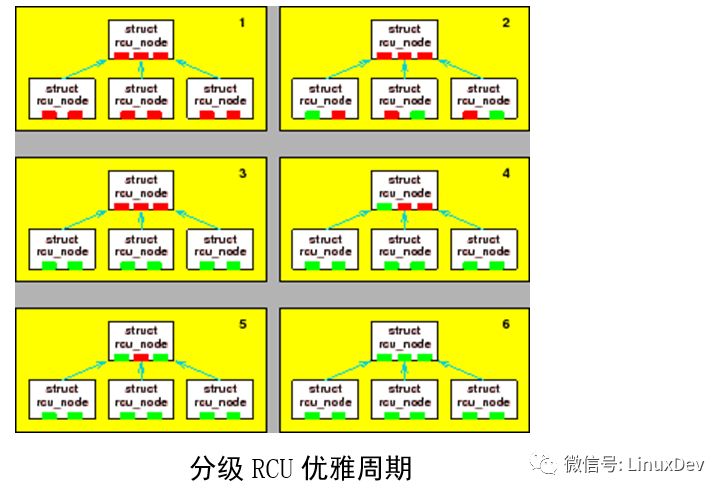
The figure above shows how to detect elegant cycles. In the first figure, no CPU has passed a static state and is marked with a red block. Assume that all 6 CPUs try to tell the RCU at the same time that they have passed a stationary state. Then, in each pair of CPUs, only one of the CPUs can obtain the lock of the underlying rcu_node structure. In the second figure, it is assumed that CPU0, 3, and 5 are relatively lucky to obtain the lock of the underlying rcu_node structure, which is identified as a green block in the figure. Once these lucky CPUs are finished, other CPUs will get the locks, as shown in Figure 3. Of the three CPUs, each CPU will find that they are the last CPU in the group, so all three CPUs try to move to the upper rcu_node. At this point, only one of them can get the upper rcu_node lock. We assume that CPU1,2,4 get locks in order, then the fourth, fifth, and sixth figures show the corresponding state. Finally, Figure 6 shows that all CPUs have passed a quiescent state, so the grace period is over.
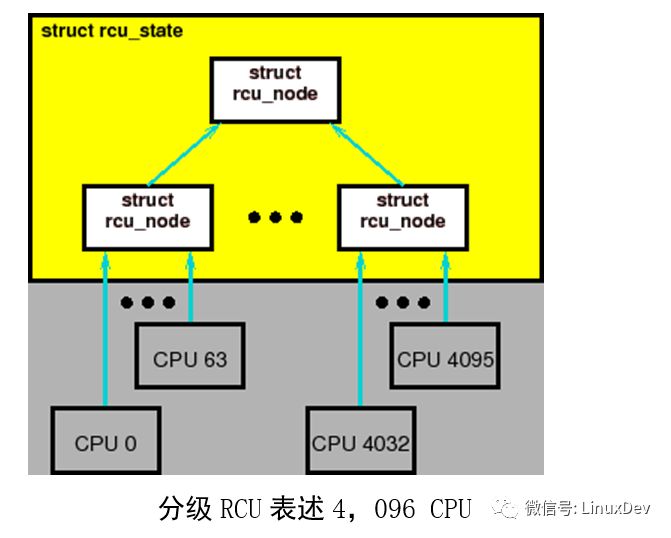
In the above sequence, no more than 3 CPUs compete for the same lock. Compared with the classic RCU, we would be pleased to find that all 6 CPUs in the classic RCU may conflict. However, for more CPUs, conflicts between locks can be significantly reduced. Consider the underlying structure of 64 and the grouping structure of 64*64=4,096 CPUs, as shown in the figure above.
Here, each lock of the underlying rcu_node structure is applied by 64 CPUs, and a competition from a single lock of 4096 CPUs of the classic RCU is reduced to 64 CPUs. During a particular grace period, only one of the CPUs in the underlying rcu_node will apply for the lock of the superior rcu_node. In this way, the lock competition is reduced by 64 times compared to the classic RCU.
2.5. Towards immature RCU implementation
As noted earlier, an important goal of these efforts is to keep a CPU that is asleep to keep it asleep to save energy. In contrast, the classic RCU wakes up every sleepy CPU for at least one elegant cycle. When most other CPUs are idle, these individual CPUs perform rcu writes, making this approach less than optimal. This situation will occur in periodic high-load systems and we need to better handle this situation.
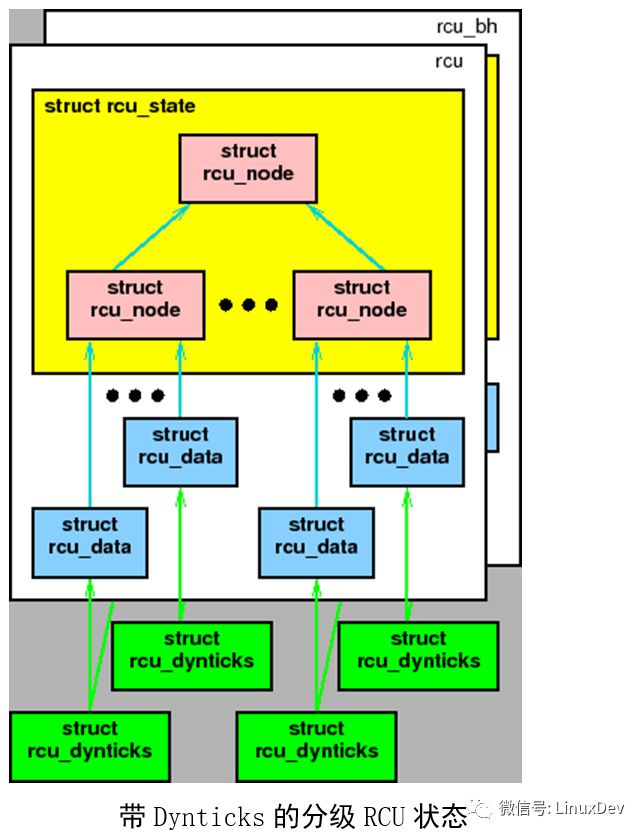
This is achieved by requiring all CPU operations to be located in a per-CPU rcu_dynticks structure. Not so accurate, when the corresponding CPU is in dynticks idle mode, the value of the counter is even, otherwise it is odd. In this way, the RCU only needs to wait for the CPU whose rcu_dynticks count is odd to pass through a quiescent state without having to wake up the CPU that is sleeping. As shown above, each of the per-CPU rcu_dynticks structures is shared by the "rcu" and "rcu_bh" implementations.
2.6. State Machine
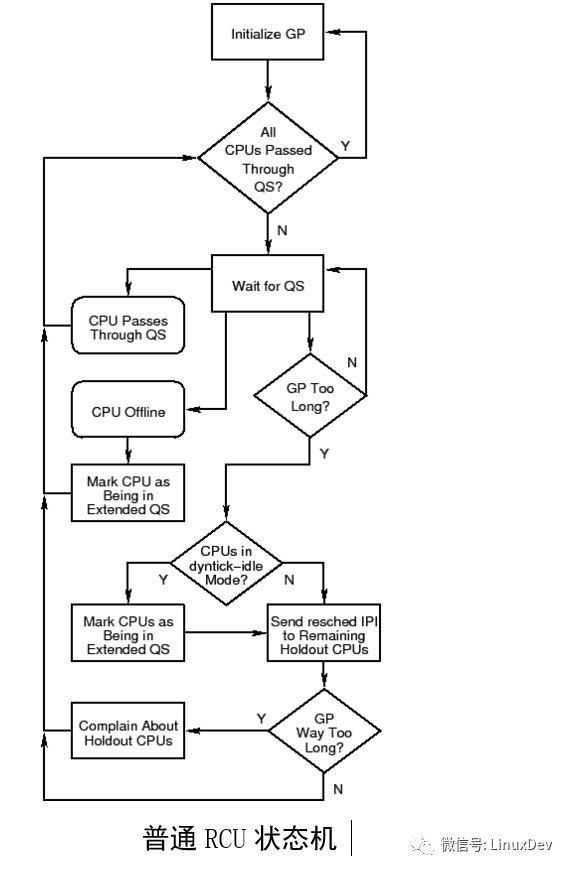
From a very high-level perspective, the Linux kernel RCU implementation can be thought of as an advanced state machine, as shown above. On a very busy system, the usual path is the top two loops. Initialize at the beginning of each grace period (GP) and wait for a quiescent state (QS). In a particular elegant cycle, when every CPU has experienced a static state, it actually does nothing. In such a system, experiencing the following events indicates a stationary state:
1, each process switch
2, in the CPU into the idle state
3, or when executing user mode code
CPU hot-plug events will cause the state machine to enter the "CPU Offline" process. The appearance of "holdout" CPUs (those that have been unable to pass through a stationary state due to software or hardware reasons) can't quickly go through a quiescent state, which will cause the state machine to enter "send reschedIPIs to Holdout CPUs". Dispatch IPI to Holdout CPUS) process. To avoid unnecessary awakening of the CPU in the dyntick-idle state, the RCU implementation will mark these CPUs in an extended quiescent state, leaving the "CPUs in dyntick-idle Mode?" via the "Y" branch (but note that these are in dyntick- The idle mode CPU will not be sent to reschedule the IPI). Finally, if CONFIG_RCU_CPU_STALL_DETECTOR is turned on, arriving too late will put the state machine into Complain About Holdout CPUs flow.
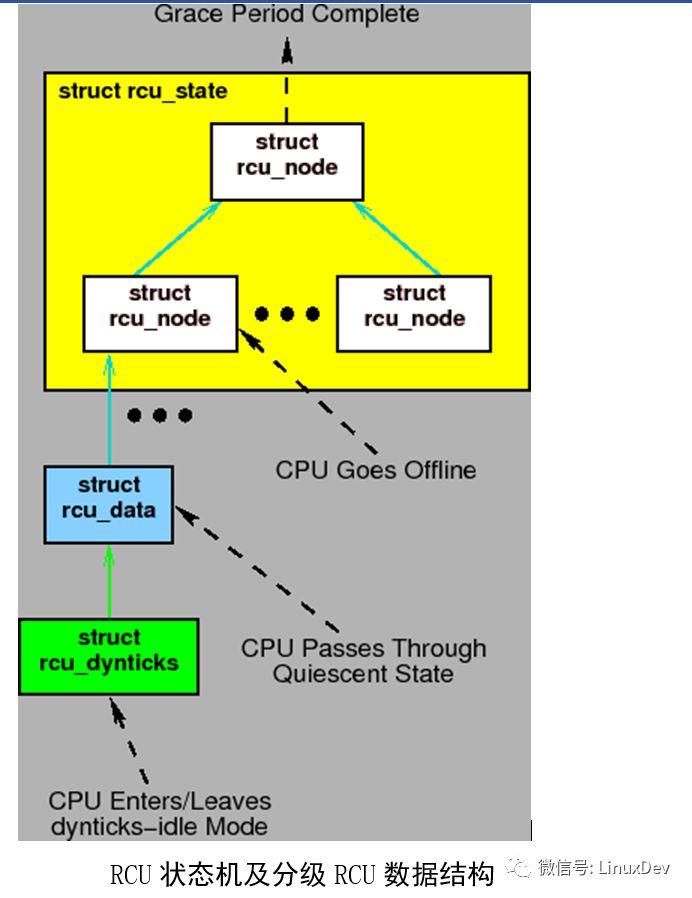
In the state diagram above, events interact with different data structures. However, the state diagram is not translated directly into C code by any RCU implementation. Instead, these implementations are coded as event-driven systems in the kernel. We represent these events through some use cases.
2.7. Use Case
These event-driven use cases include:
1. Start a new elegant cycle
2. Experience a static state
3. Announce a static state to the RCU
4. Enter and exit Dynticks Idle mode
5. Entering Interrupt from Dynticks Idle Mode
6. Enter NMI from Dynticks Idle Mode
7. Mark a CPU in Dynticks Idle mode
8.CPU is offline
9.CPU online
10. Detect a long period of elegance
2.7.1. Start a New Elegance Cycle
The rcu_start_gp() function starts a new elegant cycle. When a CPU exists callback, and this callback needs to wait for grace period, you need to call this function.
The rcu_start_gp() function updates the state in the rcu_state and rcu_data structures to identify the beginning of a new grace period, acquires the ->onoff lock (and closes the interrupt) to prevent any concurrent CPU hot-plug operations, set in all rcu_node structures Bit to identify all CPUs (including the current CPU) must go through a quiescent state and finally release the ->onoff lock.
Setting up bit operations takes place in two phases. First, the non-leaf node rcu_node bits are set without holding any locks, and then, with ->lock, the bits of the rcu_node structure of each leaf node are set.
2.7.2. Going through a static state
Rcu and rcu_bh have their own set of static states.
The rest state of the RCU is process switching, IDLE (regardless of dynticks or IDLE loops), and execution of user-state programs.
The RCU-bh's quiescent state exits the soft interrupt when the interrupt is on.
It should be noted that the rest state of rcu is also the rest state of rcu_bh. The static state of rcu is recorded by calling rcu_qsctr_inc(). The rest state of rcu_bh is recorded by calling rcu_bh_qsctr_inc(). These two functions record their status in the current CPU's rcu_data structure. Please note that in the 2.6.32 release, the rcu_qsctr_inc and rcu_bh_qsctr_inc functions have been renamed. How to use git to find out why they were renamed, this task is left to the author as an exercise.
These functions are called in the scheduler, __do_softirq() and rcu_check_callbacks(). This latter function is called during a scheduled clock interrupt and analyzes the status to determine if the interrupt occurred in a quiescent state to determine whether rcu_qsctr_inc() or rcu_bh_qsctr_inc() was called. It also triggers the RCU_SOFTIRQ soft interrupt and causes the current CPU to call rcu_process_callbacks() in the context of a subsequent soft interrupt. The rcu_process_callbacks function handles the RCU callback function on each CPU to free up resources.
2.7.3. Declaring a Standstill to the RCU
The aforementioned rcu_process_callbacks() function accomplishes several things:
1. Determine when to end a long grace period (via force_quiescent_state()).
2. When the CPU detects the grace period, use the appropriate action. (via rcu_process_gp_end()). "Appropriate actions" include speeding up the CPU's callbacks and recording new elegant cycles. The same function also updates the status in response to other CPUs.
3. Report the current CPU's inactivity to the RCU core mechanism. (Using rcu_check_quiescent_state(), it will call cpu_quiet()). Of course, this process will also mark the end of the current grace period.
4. If no grace period is processed and the CPU has an RCU callback waiting for the grace period, a new grace period begins (via cpu_needs_another_gp() and rcu_start_gp()).
5. When the grace period is over, call the CPU's callback (via rcu_do_batch()).
These interfaces are carefully implemented to avoid BUGs, such as: bugs that report static status from the previous grace period to the current grace period.
2.7.4. Entering and Exiting Dynticks Idle Mode
The scheduler calls rcu_enter_nohz() to enter dynticks-idle mode and calls rcu_exit_nohz() to leave this mode. The rcu_enter_nohz() function increments the per-CPU dynticks_nesting variable and also increments the per-CPU dynticks counter. The latter must then have an even number. The rcu_exit_nohz() function decrements the per-CPU dynticks_nesting variable and once again increments the per-CPU dynticks counter, which will have an odd value.
The dynticks counter can be sampled by other CPUs. If its value is even, the CPU is in an extended standstill. Similarly, if the counter changes during a particular grace period, the CPU must be in an extended standstill at some point during the grace period. However, we need to sample another dynticks_nmi per CPU variable, which we will discuss later.
2.7.5. Entering Interrupts from Dynticks Idle Mode
The interrupts entered from dynticks idle mode are handled by rcu_irq_enter() and rcu_irq_exit(). The rcu_irq_enter() function increments the per-CPU dynticks_nesting variable. If this variable is 0, it also increments the dynticks per-CPU variable (it will have an odd value).
The rcu_irq_exit() function decrements the per-CPU dynticks_nesting variable. And, if the new value is 0, it also increments dynticks per CPU variable (it will have an even number).
Note: entering the interrupt will deal with the exit dynticks idle mode, and vice versa. The inconsistency between entry and exit may cause some confusion, without warning you should also want to get this.
2.7.6. Entering NMI from Dynticks Idle Mode
Entering NMI from dynticks idle mode is handled by rcu_nmi_enter() and rcu_nmi_exit(). These functions increment the dynticks_nmi counter at the same time, but only if the aforementioned dynticks count is even. In other words, if the NMI occurs in non-dynticks-idle mode or in an interrupted state, the NMI will not operate the dynticks_nmi counter.
The only difference between these two functions is the error check, rcu_nmi_enter() must make the dynticks_nmi counter an odd value, and rcu_nmi_exit() must make this counter even.
2.7.7. Marking the CPU in Dynticks Idle Mode
The force_quiescent_state() function implements a three-phase state machine. The first stage (RCU_INITIALIZING) waits for rcu_start_gp() to complete the grace period initialization. This state does not exit from force_quiescent_state(), it exits from rcu_start_gp().
In the second stage (RCU_SAVE_DYNTICK), the dyntick_save_progress_counter() function scans the CPUs that have not yet reported a stationary state, recording their per-CPU dynticks and dynticks_nmi counters. If these counters are even values, then the corresponding CPUs are in the dynticks-idle state, so they are marked as extended static (reported by cpu_quiet_msk()).
In the third stage (RCU_FORCE_QS), the rcu_implicit_dynticks_qs() function once again scans the CPU that has not yet reported a quiescent state (either explicitly marked or implicitly flagged in the RCU_SAVE_DYNTICK stage) and again checks the dynticks per CPU and dynticks_nmi counters. If each value is changed, or is currently an even number, the corresponding CPU has already passed a stationary state or is currently in a dynticks idle mode, that is, the aforementioned extended stationary state.
If rcu_implicit_dynticks_qs() finds that a particular CPU is neither in dynticks idle mode nor does it report a static state, it calls rcu_implicit_offline_qs(). This function checks if the CPU is offline and if so, it also reports an extended quiescent state. If the CPU is online, rcu_implicit_offline_qs() sends a rescheduled IPI attempting to alert the CPU that it should report a standstill to the RCU.
Note that force_quiescent_state() neither directly calls dyntick_save_progress_counter() nor calls rcu_implicit_dynticks_qs() directly, but instead passes them to the rcu_process_dyntick() function. This function abstracts the generic code that scans the CPU and reports the extended static state.
2.7.8. CPU is Offline
The CPU offline event causes rcu_cpu_notify() to call rcu_offline_cpu(), and rcu and rcu_bh call __rcu_offline_cpu() in sequence. This function clears the offline CPU's bit so that later grace periods will no longer expect the CPU to declare a standstill, and then call cpu_quiet() to announce an offline extended standstill. This is performed with a global->onofflock lock, to prevent conflicts with elegant cycle initialization.
2.7.9. CPU goes online
The CPU online event causes rcu_cpu_notify() to call rcu_online_cpu() to initialize the CPU's dynticks state, then call rcu_init_percpu_data() to initialize the CPU's rcu_data data structure, and also set the CPU's bit (also protected by global->onofflock). The graceful period behind will wait for this CPU to be stationary. Finally, rcu_online_cpu() sets the CPU's RCU soft interrupt vector.
2.7.10. Detection of long elegant cycles
When the CONFIG_RCU_CPU_STALL_DETECTOR kernel parameter is configured, the record_gp_stall_check_time() function records the current time and the timestamp after 3 seconds. If the current grace period does not end after expiration, the check_cpu_stall function will detect the culprit. And print_cpu_stall() is called if the current CPU is causing the delay, and print_other_cpu_stall() is called if it is not. The time difference between the two jiffies helps to ensure that other CPUs report their status when possible. With this time difference, the CPU can do something like track its own stack.
2.8. Test
The RCU is the basic synchronization code, so the RCU's error results in a random, hard-to-debug memory error. Therefore, a highly reliable RCU is very important. These depend on careful design, but in the end it still needs to rely on high-strength stress tests.
Fortunately, although there are some disputes about coverage, there are still some stress tests on the software. In fact, conducting these tests is highly recommended because it will in turn torture you if you don't test your software for torture. This kind of torture comes from the fact that it crashes when it is not appropriate.
Therefore, we use the rcutorture module to stress test the RCU.
However, testing the RCU based on the RCU usage in normal situations is not yet sufficient. It is also necessary to conduct stress tests against unusual situations. For example, the CPU is concurrently online or offline, and the CPU concurrently enters and exits the dynticks idle mode. Paul uses a script CodeSamples and uses the test_no_idle_hz module parameter to stress test the dynticks idle mode to the module rcutorture. Sometimes the author is also suspicious, so try to run a kernbench load test program when testing. Running a 10-hour stress test on a 128-way machine seems to be enough to test out almost all BUGs.
In fact, this is not finished yet. Alexey Dobriyan and Nick Piggin demonstrated as early as 2008 that it is necessary to stress test the RCU with all relevant kernel parameter combinations. The relevant kernel parameters can be identified using another script, CodeSamples.
1. CONFIG_CLASSIC_RCU: Classic RCU.
2. CONFIG_PREEMPT_RCU: Preemptive (real-time) RCU.
3. CONFIG_TREE_RCU: Classic RCU for large SMP systems.
4.CONFIG_RCU_FANOUT: The number of child nodes for each rcu_node.
5.CONFIG_RCU_FANOUT_EXACT: balance the rcu_node tree.
6.CONFIG_HOTPLUG_CPU: Allows CPU to go online and offline.
7.CONFIG_NO_HZ: Open dyntick-idle mode.
8.CONFIG_SMP: Opens the multi-CPU option.
9. CONFIG_RCU_CPU_STALL_DETECTOR: Perform RCU detection when the CPU enters an extended quiescent state.
10.CONFIG_RCU_TRACE: Generate RCU trace files in debugfs.
We ignore the CONFIG_DEBUG_LOCK_ALLOC configuration variable because we assume that the hierarchical RCU cannot interrupt lockdep. There are still 10 configuration variables, and if they are independent booleans, they result in 1024 combinations. Fortunately, first of all, the first three are mutually exclusive, which can reduce the number of combinations to 384, but CONFIG_RCU_FANOUT can take a value of 2-64, increasing the number of combinations to 12,096. It is impossible to implement such a large number of combinations.
The key point is: if CONFIG_CLASSIC_RCU or CONFIG_PREEMPT_RCU is valid, only CONFIG_NO_HZ and CONFIG_PREEMPT are expected to change their behavior. This almost reduced the two-thirds of the portfolio.
Moreover, not all of these possible CONFIG_RCU_FANOUT values ​​will produce significant results. In fact, only part of the situation needs to be tested separately:
1. Single node "tree".
2. Two-level balance tree.
3. Three-level balance tree.
4. Automatically balance the tree. When CONFIG_RCU_FANOUT specifies an unbalanced tree but CONFIG_RCU_FANOUT_EXACT is not configured, automatic balancing occurs.
5. Unbalanced tree.
Furthermore, CONFIG_HOTPLUG_CPU is only useful when CONFIG_SMP is specified and CONFIG_RCU_CPU_STALL_DETECTOR is independent, so it only needs to be tested once (although some people are more suspicious than me, they may decide to test it both with CONFIG_SMP and without CONFIG_SMP). Similarly, CONFIG_RCU_TRACE only needs to be tested once. However, someone as suspicious as me would choose to test it with CONFIG_NO_HZ and without CONFIG_NO_HZ.
This allows us to get a RCU test with better coverage in 15 test scenarios. All of these test scenarios specify the following configuration parameters to run the rcutorture so that CONFIG_HOTPLUG_CPU=n produces the actual effect:
CONFIG_RCU_TORTURE_TEST=m
CONFIG_MODULE_UNLOAD=y
CONFIG_SUSPEND=n
CONFIG_HIBERNATION=n
15 tests with the following example:
1. Mandatory single node "tree" for small systems:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=8
CONFIG_RCU_FANOUT_EXACT=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
2. Force a two-level node tree for large systems:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=4
CONFIG_RCU_FANOUT_EXACT=n
CONFIG_RCU_TRACE=n
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
Force a three-level node tree for very large systems:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=2
CONFIG_RCU_FANOUT_EXACT=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
4. Test the automatic balance:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=6
CONFIG_RCU_FANOUT_EXACT=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
5. Test the imbalance tree:
CONFIG_NR_CPUS=8
CONFIG_RCU_FANOUT=6
CONFIG_RCU_FANOUT_EXACT=y
CONFIG_RCU_CPU_STALL_DETECTOR=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
6. Disable CPU delay detection:
CONFIG_SMP=y
CONFIG_NO_HZ=y
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
7. Disable CPU delay detection and dyntick idle mode:
CONFIG_SMP=y
CONFIG_NO_HZ=n
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
8. Disable CPU delay detection and CPU hot swap:
CONFIG_SMP=y
CONFIG_NO_HZ=y
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
9. Disable CPU delay detection, dyntick idle mode, and CPU hot swap:
CONFIG_SMP=y
CONFIG_NO_HZ=n
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
10. SMP, CPU delay detection, dyntick idle mode, and CPU hot swap are disabled:
CONFIG_SMP=n
CONFIG_NO_HZ=n
CONFIG_RCU_CPU_STALL_DETECTOR=n
CONFIG_HOTPLUG_CPU=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
This combination has some compilation warnings.
11. Suppress SMP, prohibit CPU hot swap:
CONFIG_SMP=n
CONFIG_NO_HZ=y
CONFIG_RCU_CPU_STALL_DETECTOR=y
CONFIG_HOTPLUG_CPU=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=y
12. Test classic RCU with dynticks idle but without preemption:
CONFIG_NO_HZ=y
CONFIG_PREEMPT=n
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=y
CONFIG_TREE_RCU=n
13. Test classic RCU when there is preemption but no dynticks idle:
CONFIG_NO_HZ=n
CONFIG_PREEMPT=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=n
CONFIG_CLASSIC_RCU=y
CONFIG_TREE_RCU=n
14. In the case of dynticks idle, the test can preempt the RCU:
CONFIG_NO_HZ=y
CONFIG_PREEMPT=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=y
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=n
15. When there is no dynticks idle, the test can preempt the RCU:
CONFIG_NO_HZ=n
CONFIG_PREEMPT=y
CONFIG_RCU_TRACE=y
CONFIG_PREEMPT_RCU=y
CONFIG_CLASSIC_RCU=n
CONFIG_TREE_RCU=n
For each major change affecting the RCU core code, the rcutorture should be run with the above combination, and CPU hot-swapping should be performed concurrently with CONFIG_HOTPLUG_CPU. For small changes, run kernbench in each case. Of course, if the change is only limited to a subset of the configuration parameters, the number of test cases can be reduced.
The author strongly recommends stress testing software: Geneva Convention!
2.9. Conclusion
This graded RCU implementation reduces lock contention and avoids unnecessary wake-ups of the dyntick-idle sleep state of the CPU, thus helping to debug Linux CPU hot-swapping code. This implementation is designed to handle large systems with thousands of CPUs, and on a 64-bit system, the CPU limit is 250,000. This limit is not a problem for some time to come.
Of course, this RCU implementation also has some limitations:
1.force_quiescent_state() may scan the entire CPU set with an interrupt. This is a major drawback in real-time RCU implementations. Therefore, if you need to add a rating to a preemptable RCU, you need other methods. In a system with 4096 CPUs, it may cause some problems, but it needs to be tested in an actual system to prove that there are really problems.
In a busy system, it cannot be expected that the force_quiescent_state() scan will occur and the CPU will experience a quiescent state in the three jiffies after starting a static state. In a semi-busy system, only the CPU in the dynticks-idle mode needs to scan. In other cases, for example, during an dynticks-idle CPU scan, subsequent scans are needed when dealing with an interrupt. However, such scans are performed on the respective CPUs, so the corresponding scheduling delay only affects the CPU load on which the scan process is located.
If scanning proves to be a problem, a good method is to perform incremental scans. This will add a little bit of code complexity and increase the time to end the elegant cycle, but this is indeed a good solution.
2. The rcu_node hierarchy is created at compile time, so its length is the maximum number of CPUs NR_CPUS. However, even on a system with 4,096 CPUs, the rcu_node hierarchy consumes only 65 cache lines on a 64-bit system. (This is true even if you include 4,096 CPUs on a 32-bit system!). Of course, in a 16-CPU system, configuring NR_CPUS=4096 will use a secondary tree, and in this case, the single-node tree will work fine. Although this configuration will increase the load on the lock, it will not actually affect the read-end code that is executed frequently, so it will not be a big problem.
3. This patch will slightly increase the kernel code and data size: In the NR_CPUS=4 system, from the classic RCU's 1,757 byte kernel code, 456 bytes of data, a total of 2213 bytes of kernel size, while the graded RCU Increased to 4,006 bytes of kernel code, 624 bytes of kernel data, a total of 4,630 bytes in size. Even for most embedded systems, this is not a problem. These systems typically have more than one megabyte of main memory. But for extremely small systems, this may be a problem, and two types of RCU implementations need to be provided to satisfy such embedded systems. However, there is an interesting problem. In such a system, perhaps only one CPU is included. Such a system can be implemented with a particularly simple RCU.
Even with these problems, this hierarchical RCU implementation is still a huge improvement over the classic RCU in hundreds of CPU systems. Finally, it should be noted that the classic RCU is designed for 16-32 CPU systems.
In some places, it is necessary to use grading in preemptible RCU implementations.
Subsequent chapters will continue to analyze the code of the graded RCU and the implementation of some other RCUs in Linux. There may also be discussions about how to develop complex parallel software like RCU and its formal verification.
Since AC power cord is output of high voltage electric power, there is a risk of electric shock injury, therefore, All the AC power cord must comply with safety standard to produce. AC (Alternating Current) Power cord is to transmit high voltage. It is used to drive machinery or home appliances.
AC Power cord,power cable, batter cable, power cord
ETOP WIREHARNESS LIMITED , https://www.oemwireharness.com