Lei Fengwang (search for "Lei Feng Net" public concern) : In the last article, we saw the urgency of deep learning for computation. And introduced a processor that Intel designed for this: Code-named KNL (Knights Landing) high-performance CPU Xeon Phi. In the next article, we will show you some of the adjustments and improvements that deep learning language developers have made to meet these needs and new hardware.
At the end of the article, Caffe, a famous open source learning framework, was mentioned. However, the original version of the Caffe language from Berkeley University took too long to process the data, and it does not support multi-node, parallel file systems by default. Therefore, it is not very good at hyper-scale deep learning operations. However, since Caffe is open source, it is theoretically possible for anyone to make improvements that they need. The various functions of Caffe have in fact been improved to support the potential of cluster parallel computing. The Inspur Group, based on the original Caffe, has developed the first version of Caffe that supports cluster parallel computing on KNL. Intel's Luster memory, OPA network, and KNL clusters are supported.

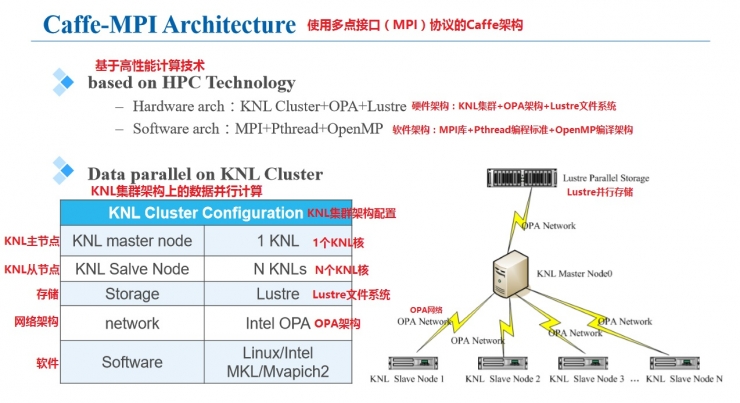
Inspur Group named this improved version of the Caffe framework as the Caffe architecture. The following figure shows some explanations about the structure of Caffe-MPI when it operates on KNL. It can be seen that the calculation process adopts MPI master-slave mode, using multiple KNL processors to form a node network, the master node uses a KNL, and the slave nodes can be composed of N KNLs as required due to the use of Lustre designed specifically for HPC. File system, so data throughput is not limited to calculations and training. The OPA architecture also ensures smooth network communications. On the software system side, Linux/Intel MKL and Mvapich2 are supported.
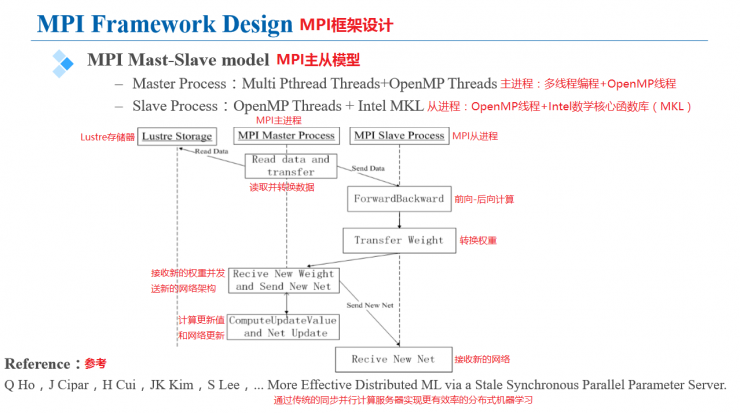
The main node in the design framework is MPI single process + multiple Pthread threads, and the slave nodes are MPI multiprocesses. The figure shows the block diagram of the entire network training.
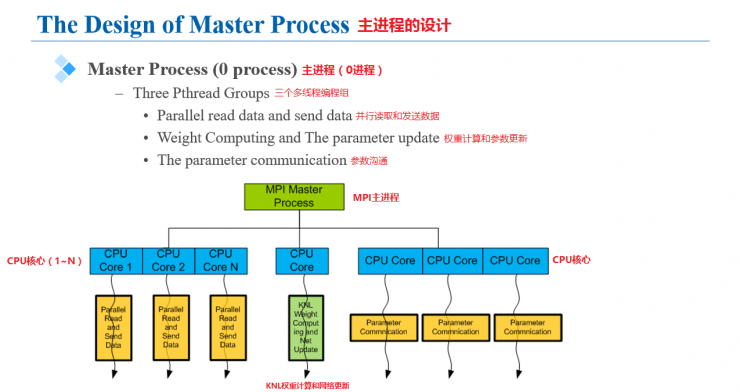
Up to 72 cores of KNL can be fully utilized in the design. The main process can handle three threads simultaneously: reading and sending data in parallel, calculating weights and parameters, and communicating parameters between networks. The illustration is given in the figure below.
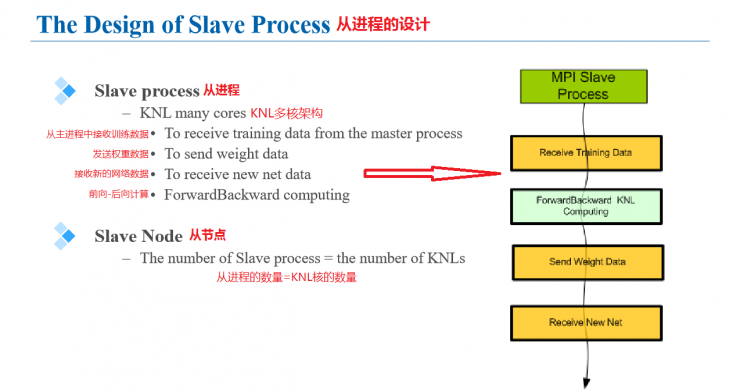
The main processing flow of the slave process in the MPI structure is: receiving training data from the master process, sending weight data, receiving new network data, and performing forward and backward calculations. Each KNL core in the slave node network represents a slave node in an MPI network.
The information in the figure below shows that the improved version of the Caffe-MPI framework running on the KNL cluster performs several optimizations on the original Caffe. The final performance is 3.78 times that of the original. Increased performance extension efficiency by 94.5% when increasing the total number of KNL processors

FPGA is another hardware that has great potential in deep learning.

At present, Inspur, Altera, and HKUST have achieved very good results in the application of FPGAs in the field of online identification. The results show that the system composed of FPGAs is significantly superior to the system composed of traditional CPUs in terms of various indicators.

The conclusion is that for offline learning, the MPI-Caffe architecture built on the KNL processor can do a good job. Online awareness projects such as online voice platforms are very suitable for building systems using FPGAs.
