Abstract: Based on the discussion of audio watermarking technology and its development, some important algorithms of audio digital watermarking are reviewed. A clear watermarking algorithm based on discrete wavelet analysis combined with human auditory characteristics is proposed.
This article refers to the address: http://
In recent years, the rapid development of network technology and the rapid spread of computers have made information exchange, editing and distribution very easy. While the development of information technology has brought convenience and convenience to human life, it has also been used by some lawless elements to defraud computers. It also faces serious challenges. Combating lawless elements has become a real problem that urgently needs to be resolved. Digital watermarking is a technology that meets these requirements.
Earlier, using the block DCT watermarking technique, their watermarking scheme uses a key to randomly select some blocks of the image, and slightly changes a triplet in the frequency domain's intermediate frequency to hide the binary sequence information. This method is robust to lossy compression and low pass filtering. Cox et al. [proposed a famous digital watermarking technique based on image global transform, which makes discrete cosine transform (DCT) for the whole image. Barni et al. proposed a DCT-based watermarking algorithm using HVS masking characteristics in the watermark embedding stage. The DCT transform of the image is performed, and the DCT coefficients are rearranged into a one-dimensional vector by Zig-Zag scanning, leaving the L coefficients starting in the vector unchanged, and the M coefficients following the Lth coefficient are modified to be embedded. Watermark. Based on the qualitative and quantitative analysis of DC and AC components of DCT coefficients, Huang Jiwu pointed out that DC component is more suitable for embedding watermark than AC component, watermark embedded with DC component has better robustness, and a DC is proposed. Adaptive algorithm for components.
Digital Watermarking technology embeds some identification information (ie, digital watermark) directly into a digital carrier (including multimedia, documents, software, etc.) or indirectly (modifies the structure of a specific area) without affecting the use of the original carrier. Value is not easy to detect and modify again. But it can be recognized and recognized by the producer. Through the information hidden in the carrier, it is possible to confirm the content creator, the purchaser, transmit the secret information, or determine whether the carrier has been tampered with. Digital watermarking is an important research direction of information hiding technology. Digital watermarking is an effective way to achieve copyright protection and an important branch of research in information hiding technology. This paper briefly introduces several important algorithms of digital watermarking, and proposes an audio digital watermarking model based on discrete wavelet transform (DWT), and gives some experimental results.
1 audio watermark
The main application of audio digital watermarking is covert communication and copyright protection. Covert communication emphasizes the concealment of information and the embedded capacity of data, while copyright protection emphasizes robustness. Watermarking techniques currently applied to digital copyright protection of audio products are mostly limited to non-compressed domains, including time domain and transform domain. The time domain mainly has LSB algorithm and echo algorithm, and the transform domain algorithm mainly uses DCT, DFT and DWT.
The most important algorithms for embedding audio digital watermarks are the following:
(1) The least significant bit embedding (LSB-Lesat Significant Bit) is one of the simplest embedding methods. Any form of watermark can be converted into a stream of binary streams. Each sampled data of an audio file is also represented by a binary value. This allows the watermark to be embedded in the audio signal by replacing the least significant bit (usually the lowest bit) of each sample value with a binary bit representing the watermark. If the audio signal is regarded as the channel for watermark transmission, the watermark is regarded as the signal transmitted in the channel. Ideally, the channel capacity will be 1 Kbps/kHz, that is, the sampling rate and the bit rate are numerically equivalent. The pseudo-random sequence can be generated by a pseudo-random sequence generator. When the pseudo-random sequence generator has a fixed structure, different initial values ​​will generate different pseudo-random sequences, so that the transmitting and receiving parties only need to secretly transmit an initial value as a key without transmitting the entire pseudo-random sequence value. To enhance watermark robustness, consider adding a watermark to the high frequency components of the audio data.
The LSB method is simple and easy, with large data capacity and high security. The disadvantage is that the robustness against signal processing is poor.
(2) Spreading method (Spread Sprectrum Encoding). This method encodes the information stream by distributing the encoded data into as many spectra as possible. Commonly used are Direct Sequence Spread Spectrum Coding (DSSS), which is usually combined with an excellent m-sequence for encoding and decoding. In order to utilize the masking effect of HAS, it is generally necessary to perform several levels of filtering processing on the sequence used, and the detection of the watermark is combined with the correlation hypothesis test detection method. This method has certain robustness to MP3 audio coding, PCM quantization and additional noise. The spread spectrum method has good anti-interference performance, strong concealment, small interference, easy to implement code division multiple access, and digital mode compatibility.
(3) Phase encoding. Utilizing the characteristics of the human ear hearing system that are insensitive to absolute phase and sensitive to relative phase, the reference phase representing the watermark information is used to replace the absolute phase of the original audio segment, and the remaining audio segments are adjusted to maintain the relative phase constant. The coding steps are briefly described as follows:

6 Perform an IDFT inverse transform based on the modified phase matrix and the original amplitude matrix to generate an audio signal containing the watermark.
(4) Echo hiding. The watermark data is embedded into the audio signal by introducing echo, which takes advantage of another characteristic of the HAS: the backward shielding of the audio signal in the time domain, ie the weak signal is masked after the strong signal disappears, approximately 50 ms after the strong signal disappears. Continue to function within ~200ms without being noticed by the human ear.
Since echo hiding is an environment in which watermark information is used as carrier data rather than random noise embedded in the carrier data, there is satisfactory robustness to some lossy compression algorithms.
(5) Transform domain algorithm: The transform domain algorithm has many advantages that the spatial domain algorithm does not have, the most prominent of which is the robustness of its algorithm. Transform domain algorithms include discrete Fourier transform (DFT), discrete cosine transform (DCT), and discrete wavelet transform (DWT) that has emerged in recent years. For the first two methods, quite a lot of research has been done at home and abroad. The basic idea is to transform the original audio data in a certain frequency domain in combination with the HAS auditory characteristics, and then change the corresponding transform coefficients to embed the watermark. The algorithm in this paper is based on the third transform, discrete wavelet transform. Here is a brief introduction to DWT technology.
The DWL algorithm performs L-level wavelet decomposition using the original audio of the Daubechies-4 wavelet base, retains the difference components of the previous L-1 level, and processes the detail components of the L-th level and embeds the watermark. A feature of this algorithm is that the watermark signal is placed in the low frequency portion of the most concentrated speech signal energy.
2 human hearing model
The response of the human auditory system to the input signal is frequency based, and the difference in pitch corresponds to a change in frequency. Figure 1 shows the sensitivity of the human ear as a function of frequency. The figure shows the lowest sound intensity that can be heard by the human ear. For each different frequency, it is exactly the reciprocal of the audio sensitivity. As can be seen from Figure 1, the human ear is most sensitive to frequencies around 3 kHz, and the sensitivity of the human ear is reduced for frequencies that are too high (20 kHz) and too low (20 Hz).
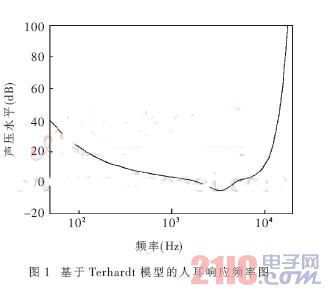
According to this characteristic, it can be known that the watermark is embedded in the appropriate high frequency or low frequency component of the audio data, and it can be reasonably expected not to destroy the quality of the original audio. This can be verified from subsequent experiments.
3 algorithm
The algorithm adopts DWT and includes three main parts: watermark embedding, watermark detection and watermark attack. The working principle of the watermark is shown in Figure 2. The detection of the watermark requires raw audio data.
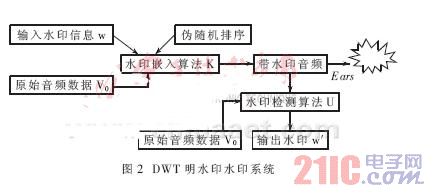
3.1 Watermark Embedding Algorithm
(1) Scrambling the watermark image to be embedded. The algorithm simply uses a pseudo-random number algorithm to eliminate the correlation of data. (2) The original audio data is subjected to multi-scale one-dimensional decomposition, and the low-frequency coefficients and the three-layer high-frequency coefficients are respectively extracted. In order to obtain better robustness, the algorithm embeds the watermark data into the third layer of high frequency components of the audio data. (3) Embedding watermark data according to the formula Vw(i)=V(i)+(α+e)×W(i). Where V(i) is the audio data bit, W(i) is the watermark data bit, Vw(i) is the audio data bit after embedding the watermark, α is the watermark embedding strength, and the e value is corrected as the value 10-20. Through experiments, it is found that the embedded watermark effect is ideal when the alpha value is taken as 0.004. (4) The audio after embedding the watermark data is subjected to IDWT transformation to obtain audio data including the watermark.
3.2 Watermark Detection Algorithm
(1) The multi-scale one-dimensional decomposition of the audio data containing the watermark is performed, and the three-layer high-frequency component coefficients are extracted.
(2) The detection algorithm is the inverse process of the embedded algorithm, and the original audio data is required to participate in the detection, expressed as:
W(i) = (Vw(i) - V(i)) / (α + e), where the values ​​of α and e are identical to the values ​​determined in the embedding algorithm.
(3) W(i) obtained in step (2) is the extracted one-dimensional watermark information sequence, and is subjected to up-dimensional processing to obtain a two-dimensional image form. The result is a watermark that detects the output.
The original image embedded with the watermark and the watermark extracted after one embedding are shown in Figures 3 and 4, respectively.

4 part of the test
In order to test the performance of the watermarking system, various types of attacks are performed on the watermarked audio data, and some experimental results are given here.
definition:
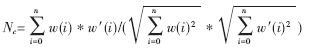
Nc is used to measure the similarity between the extracted watermark image and the original watermark image. The similarity between the watermark and the original watermark image extracted directly from the unaffected water-printed audio is as high as 0.9998.
(1) Two choices of forced selection experiments. The original audio and the watermarked audio are played separately for the tester who does not know the exact original audio signal beforehand, and the tester is required to identify the original audio. According to the conclusion of L.BONey et al. [5], if the second type of audio is said to be roughly equivalent in proportion to the original audio, it can be considered that the watermark is embedded without causing a significant difference in human perception. In the experiment, 8 students from the same laboratory were randomly selected. By embedding watermarks in different wav files and randomly asking questions, about 53.4% ​​of the respondents thought that the original audio sound quality was better. It is indicated that the watermark embedded by the system does not cause a significant change in the original audio quality.
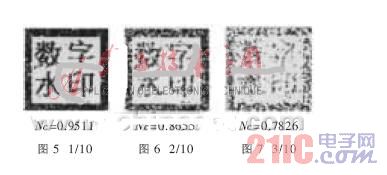
(2) The audio is truncated by n/10 (n = 1, 2, 3, ...) of all the data, and the original audio data bit length is slightly larger than 40 000, starting from the 20 000th bit.
According to FIG. 5, FIG. 6, and FIG. 7, it can be seen that after the audio is cut off by about one-third of the content, a more obvious watermark pattern can still be extracted. If the cut portion is more, the watermark cannot be satisfactorily detected. However, this result is acceptable because one-third of the shear rate will simultaneously result in a large loss of carrier audio data.
(3) MP3 compression. At present, MP3 compression coding of audio signals is a commonly used audio processing technology, and its goal is to reduce the amount of audio data as much as possible without affecting the quality of the original audio signal. Different bit rates correspond to different MP3 compression ratios. In this test, a piece of audio containing a watermark is first subjected to compression at a code rate of 96 Kbps (compression ratio of 7.4:1), and then subjected to phase-diffusion decoding processing, and the detected watermark image is as shown in FIG.

5 Conclusion
In recent years, the research work in the field of audio digital watermarking, especially in the field of transform domain audio watermark embedding and detection, has developed rapidly. Discrete wavelet analysis (DWT) is one of the hotspots in the research of digital watermarking system in recent years. The algorithm has been shown to have good concealment, and the quality of the original audio is hardly weakened, and it has certain ability to resist shear attacks and other attacks. To further improve the robustness of the algorithm, further consideration should be given to how to utilize more HAS features and the location and intensity of watermark embedding. Considering the practicality of the algorithm, consideration should be given to increasing the capacity of the embedded watermark. These are the directions that need further improvement.
Fiber Optical Distribution Box(Metal) Fiber Optic Distribution Box is specially designed for FTTH or FTTB for Indoor/Outdoor application. It is can manage single,ribbon & bundle fiber cables. It consists of splicing, distribution and panel with ensures the excess fiber cords and pigtails in good order, no interval and easy for management and operation. It offers mufti-functions of distribution management.

Indoor Fiber Optical Distribution Box(Metal)
Indoor Fiber Optical Distribution Box(Metal),Fiber Optic Distribution Cabinet,Metal Electrical Boxes,Metal Equipment Cabinet
Sijee Optical Communication Technology Co.,Ltd , https://www.sijee-optical.com