Tracker tracer is an advanced performance analysis and debugging tool. If you have used strace or tcpdump, you should not be scared by it... You are using a tracker. System trackers allow you to see a lot of things, not just system calls or data packets, because common trackers can track anything in the kernel or application.
There are plenty of Linux trackers to choose from. Since each of them has an official (or unofficial) mascot, we have plenty of choices for the kids to show.
Which one do you like to use?
I answer this question from the perspective of two types of readers: most people and performance/kernel engineers. Of course, this may change over time, so I need to update the content in a timely manner, perhaps once a year, or more often. (LCTT translation: This article was last updated in 2015)
For most people
Most people (developers, system administrators, operations staff, network reliability engineers (SRE)...) do not need to learn the underlying details of the system tracker. Here are the things you need to know and do:
1. Using perf_events for CPU profiling
You can use perf_events for CPU profiling. It can be represented graphically with a flame map. such as:
Git clone --depth1https://github.com/brendangregg/FlameGraph
Perf record -F99 -a -g -- sleep30
Perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > perf.svg
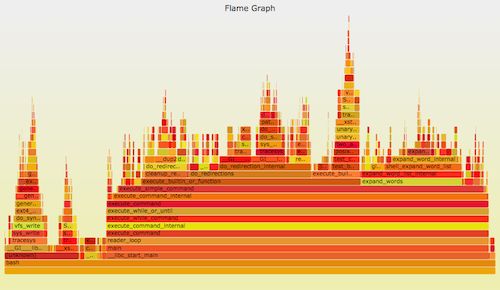
Linux's perf_events (that is, perf, which is its command) is the official tracker/parser for Linux users. It's in the kernel source and it's very well maintained (and now its functionality is fast and fast). It is usually added via the linux-tools-common package.
There are a lot of things that perf can do, but if I can only suggest you learn one of these features, then it is CPU profiling. Although from a technical point of view, this is not an event "tracking", but sampling sampling. The hardest part is getting the full stack and symbols, which was discussed in my Linux Profiling at Netflix for Java and Node.js.
2. Know what it can do
As one friend said: “You don’t need to know how the X-ray machine works, but what you need to understand is that if you swallow a coin, the X-ray machine is your choice!†You need to know how to use it. What the tracker can do, so if you really need it in business, you can learn it later, or someone who uses it.
Simply put: almost anything can be traced to understand it. Internal file system, TCP/IP processing, device drivers, internal application conditions.
3. Need a front end tool
If you want to buy a performance analysis tool (many companies sell such products) and ask for support for Linux tracking. I want an intuitive "click" interface to probe the inside of the kernel and include a delay heat map at different stack locations.
I created and open sourced some of my own front-end tools, although it is based on the CLI (not a graphical interface). This will make it easier and easier for others to use the tracker. For example, my perf-tools, tracking new processes like this:
# ./execsnoop
Tracing exec()s.Ctrl-Ctoend.
PID PPID ARGS
2289822004man ls
2290522898preconv -eUTF-8
2290822898pager -s
2290722898nroff -mandoc -rLL=164n -rLT=164n -Tutf8
[...]
At Netflix, I'm developing Vector, an instance analysis tool that is actually a front end to a Linux tracker.
For performance or kernel engineers
In general, our work is very difficult, because most people may ask us to figure out how to track an event, and therefore need to choose which tracker to use. To fully understand a tracker, you usually need to spend at least a hundred hours to use it. It's hard to understand all the Linux trackers and make the right choice between them. (I may be the only one who is close to completing this)
Here I suggest to choose the following, either:
A) Select a versatile tracker and use it as a standard. This requires a lot of time in a test environment to figure out its nuances and security. My current recommendation is the latest version of SystemTap (for example, built from source code). I know that some companies choose LTTng, although it is not very powerful (but it is very safe), but they also use it very well. It is also another candidate if you add tracking points or kprobes to sysdig.
B) Press the flowchart in my Velocity tutorial. This means using ftrace or perf_events whenever possible, eBPF is already integrated into the kernel, and then uses other trackers such as SystemTap/LTTng as a complement to eBPF. I am doing this in my current work at Netflix.
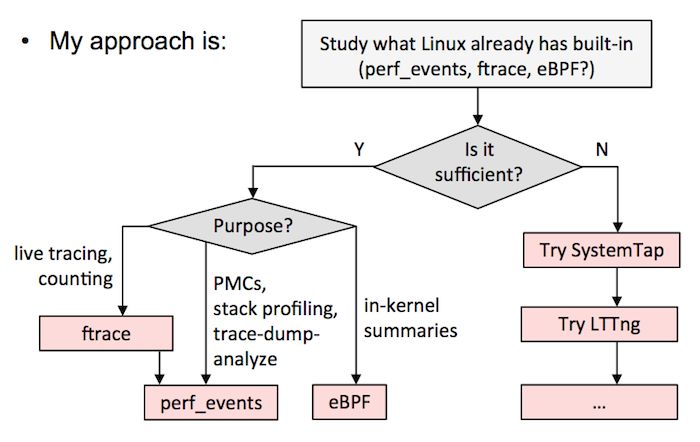
Here's my evaluation of each tracker:
Ftrace
I love ftrace, which is the best friend of the kernel hack. It is built into the kernel and can take advantage of trace points, kprobes, and uprobes to provide some functionality: event tracking with optional filters and parameters; event counting and timing, kernel overview; function flow step function-flow Walking. For an example of it, look at ftrace.txt in the kernel source tree. It is managed by /sys and is intended for a single root user (although you can use a buffered instance to support multiple users), its interface is sometimes cumbersome, but it is easier to tune hackable and has a front end: ftrace The main creator, Steven Rostedt, designed a trace-cmd, and I also created the perf-tools collection. My biggest problem is that it is not programmable programmable, so for example, you can't save and get timestamps, calculate delays, and save them as histograms. You need to dump events to the user level for post-processing, which costs some. It may be programmable via eBPF.
2. perf_events
Perf_events is the primary tracking tool for Linux users. Its source code is located in the Linux kernel and is usually added via the linux-tools-common package. It's also called perf, which refers to its front end, which is fairly efficient (dynamic caching) and is typically used to track and dump to a file (perf.data), which can then be post-processed later. It does what most ftrace can do. It can't perform function flow stepping and it's not easy to tune (and its security/error checking is better). But it can do profiling (sampling), CPU performance counting, user-level stack conversion, and use local debugging to debug line-level tracing with debuginfo debuginfo. It also supports multiple concurrent users. Like ftrace, it is not kernel programmable unless eBPF supports it (the patch is already planned). If you only learn one tracker, I suggest you learn perf, it can solve a lot of problems, and it is quite safe.
3. eBPF
Extended Berkeley Packet Filter The extended Berkeley Packet Filter (eBPF) is a kernel-in-kernel virtual machine that can run programs on events, which is very efficient (JIT). It may eventually provide in-kernel programming in-kernel programming for ftrace and perf_events, and can enhance other trackers. It is now being developed by Alexei Starovoitov and has not yet been fully integrated, but for some impressive tools, some kernel versions (eg 4.1) already support: for example, the latency thermal map of block device I/O Heat map. For more resources, check out Alexei's BPF demo and its eBPF example.
4. SystemTap
SystemTap is a very powerful tracker. It can do anything: profiling, tracking points, kprobes, uprobes (it comes from SystemTap), USDT, in-kernel programming, and more. It compiles the program into kernel modules and loads them - a method that is hard to guarantee. It was developed outside of the kernel code tree and there have been many problems in the past (kernel crashes or freezes). Many are not the fault of SystemTap - it is usually the first time to use some tracking features on the kernel and is the first to encounter bugs. The latest version of SystemTap is very good (you need to compile from its source code), but many people still haven't come out of the shadows of earlier versions. If you want to use it, take some time to test the environment, then discuss it with the developer on the #systemtap channel on irc.freenode.net. (Netflix has a fault-tolerant architecture, we use SystemTap, but we may be less worried about its security than you.) My biggest problem is that it seems to assume that you have a way to get kernel debugging information, and I There is no such information. Without it I can actually do a lot of things, but I don't have the relevant documentation and examples (I am starting to help with this myself).
5. LTTng
LTTng optimizes event collection, performs better than other trackers, and supports many event types, including USDT. Its development is done outside the kernel code tree. Its core part is very simple: write events to the trace buffer through a small fixed instruction set. This makes it both safe and fast. The disadvantage is that it is not easy to do in-core programming. I don't think that's a big problem. Because it's optimized very well, it can be fully extended, even though it needs post processing. It also explores a different analytical technique. Many "black boxes" record all events of interest so that they can be analyzed later in the GUI. I am worried that the record will miss an unexpected event, and I really need to spend some time to see how it works in practice. I spent the least amount of time on this tracker (no special reason).
6. ktap
Ktap is a promising tracker that uses a lua virtual machine in the kernel, does not require debugging information and works fine on the device when it is embedded. This makes it into the horizons of people, and at some point seems to be the best tracker on Linux. However, since eBPF began to integrate into the kernel, the integration of ktap was postponed until it was able to use eBPF instead of its own virtual machine. Since eBPF is still in the integration process after a few months, ktap developers have been waiting for a long time. I hope that it will be able to restart development later this year.
7. dtrace4linux
Dtrace4linux is mainly used by one person (Paul Fox) to use business time to port Sun DTrace to Linux. It's impressive, some provider providers work, it's not perfect, it should be at most an experimental tool (unsafe). I think the fear of licensing makes people cautious about it: it may never get into the Linux kernel because Sun is a DTrace based on the CDDL license; Paul's approach is to use it as a plugin. I would very much like to see DTrace on Linux and hope that this project will be completed. I think I will take some time to help it when I join Netflix. However, I have been using the built-in trackers ftrace and perf_events.
8. OL DTrace
Oracle Linux DTrace is a major effort to port DTrace to Linux (especially Oracle Linux). Many of the releases in the past years have been steadily improving, and developers have even talked about improving the DTrace test suite, which shows that the project is promising. Many useful features have been completed: system calls, profiling, sdt, proc, sched, and USDT. I have been waiting for fbt (function boundary tracking, dynamic tracking of the kernel), which will be a very powerful feature on the Linux kernel. Its ultimate success depends on attracting enough people to use Oracle Linux (and pay for support). Another trick is that it is not completely open source: the kernel components are open source, but I don't see the user-level code.
9. sysdig
Sysdig is a very new tracker that can handle system call syscall events using a syntax similar to tcpdump and post-process with lua. It is also impressive and it is great to see innovation in the field of system tracking. Its limitation is that its system call can only be at the time, and it dumps all events to the user level for post processing. You can do a lot of things with system calls, although I hope to see it to support trace points, kprobes, and uprobes. I also want to see it support eBPF to see an overview within the kernel. Developers of sysdig are now adding support for containers. Can pay attention to its further development.
Si-Rubber Control Cable,Si-Rubber Insulation Control Cable,Si-Rubber Sheath Control Cable,Screen Si-Rubber Control Cable
Baosheng Science&Technology Innovation Co.,Ltd , https://www.bscables.com