Shang Tang Technology published 44 papers in CVPR 2018, and achieved breakthroughs in the following areas: large-scale distributed training, human understanding and pedestrian recognition, automatic driving scenario understanding and analysis, underlying visual algorithms, and comprehensive understanding of visual and natural language , object detection, recognition and tracking, in-depth generation model, video and behavior understanding.
The following is a super-resolution algorithm for creating more natural and realistic texture images proposed by Shang Tang Technology in the field of the underlying visual algorithms. This article explains the third issue of Shangtang Technology CVPR 2018 paper.
Introduction
Single-frame image super-resolution aims at restoring a corresponding high-resolution image based on a single low-resolution image. Convolutional neural networks have shown excellent reconstruction effects in image super-resolution tasks in recent years, but restoring natural and realistic textures remains a challenge in super-resolution tasks.
How to restore the natural and true texture? An effective way is to consider the semantic category priors, that is, to use the semantic categories of the different regions in the image as the prior conditions for image super-resolution, such as sky, grass, water, architecture, forest, mountains, and plants. Textures in different categories have their own unique characteristics. In other words, semantic categories can better constrain the existence of multiple possible solutions for the same low-resolution map in super-resolution. As an example of buildings and plants shown in Figure 1, their low-resolution image blocks are very similar. Although super-recovery is combined with the generation of confrontation network (GAN), if the category prior information of the image region is not considered, the obtained result increases the texture details but does not conform to the texture features that the image region itself should have.

figure 1:
Different semantic priors
The effect of super-resolution on the image of buildings and plants
There are two problems encountered in combining semantic class priors. The first question is how to express semantic class priors, especially when there are multiple semantic categories in an image. This paper selects the semantic segmentation probability map as a prior condition, which can provide pixel-level image region information. The probability vector of each pixel can finely regulate the texture result. The second question is how to effectively integrate semantic a priori into the network. This paper proposes a new spatial feature modulation layer (SFT), which can effectively combine additional image priors (such as semantic segmentation probability maps) into the network and recover textures that are consistent with the semantic category features they belong to.
The final result shows (as shown in Figure 2) that compared with the existing SRGAN model and EnhanceNet model, the super-resolution network using the spatial feature modulation layer can generate a more natural texture, and the restored high-resolution image has more visual effects. real.

figure 2:
At 4x super resolution,
SRCNN, SRGAN, EnhanceNet
This paper compares the final results of the SFT-GAN algorithm
Spatial Feature Modulation
The spatial feature modulation layer proposed in this paper is inspired by the conditional BN layer, but the conditional BN layer and other feature modulation layers (such as FiLM) often ignore the spatial information extracted by the network, ie, for different positions of the same feature image, modulation. The parameters are consistent. However, the underlying visual tasks such as super-resolution often need to consider more image space information and perform different processing in different locations. Based on this point of view, this paper proposes a spatial feature modulation layer whose structure is shown in Figure 3.
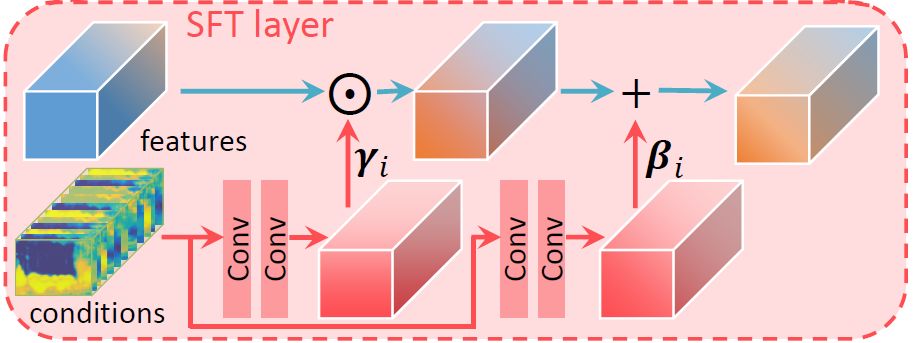
image 3:
Spatial feature modulation layer structure
The spatial characteristic modulation layer performs affine transformation on the intermediate features of the network. The parameters of the transformation are obtained by extra prior conditions (such as the semantic segmentation probability map considered in this paper) through several layers of neural networks. If F is used to represent the characteristics of the network, γ and β represent the scalar and translation parameters of the affine transformation obtained, then the output characteristics obtained by the spatial characteristic modulation layer are:
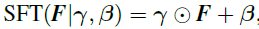
The spatial feature modulation layer can be easily integrated into existing super-resolution networks such as SRRersNet. Figure 4 is the network structure used in this article. In order to improve the efficiency of the algorithm, the semantically-segmented probability map is first subjected to a Condition Network to obtain a shared intermediate condition, and these conditions are then “broadcasted†to all SFT layers. In this paper, in the training of the network, both perceptual loss and adversarial loss are used, which is abbreviated as SFT-GAN.
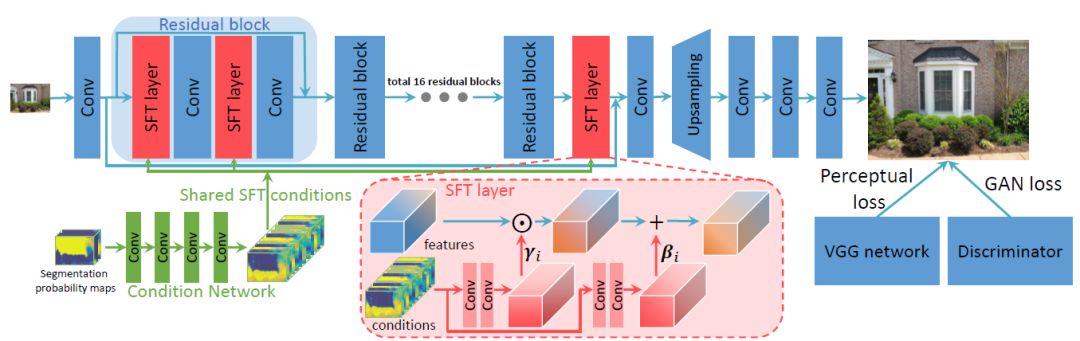
Figure 4:
Network framework diagram
Experimental results
Semantic segmentation results
As shown in FIG. 5, the current semantic learning network based on deep learning performs fine-tune on a low-resolution data set, and can generate a satisfactory segmentation effect for most scenes.
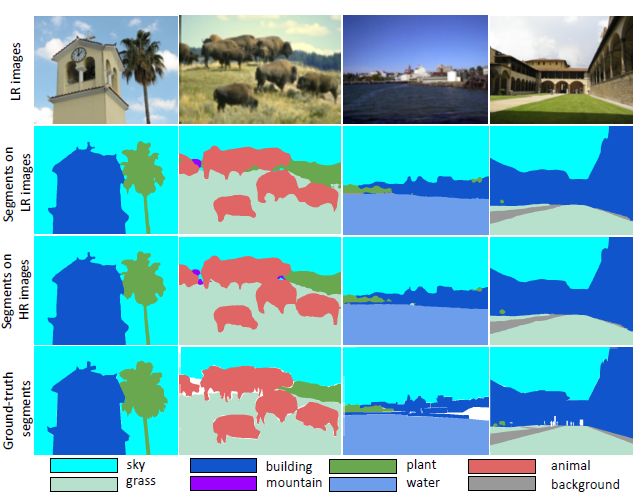
Figure 5:
Semantic segmentation results
Comparison of results of SFT-GAN and other models
Figure 6 shows the comparison of the SFT-GAN model with other model results. It can be seen that the GAN-based algorithm models SRGAN, EnhanceNet, and SFT-GAN in this paper surpass the visual model to optimize the PSNR. The SFT-GAN can generate more natural and realistic results than the SRGAN and EnhanceNet on the restoration of the texture (the animal hair in the figure, the bricks of the building, and the ripples of the water).

Figure 6:
This article SFT-GAN model
Comparison with existing super-resolution models
In the human user evaluation conducted, the SFT-GAN model also has a significant improvement over the previous GAN-based methods in various semantic categories (as shown in Figure 7).
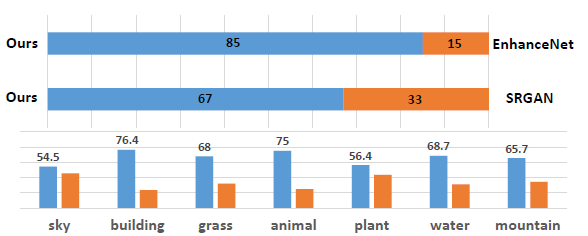
Figure 7:
Human users evaluate different algorithmic effects
Other experimental exploration
This paper also visualizes the relationship between the semantic segmentation probability map and the characteristic modulation layer parameters. Figure 8 shows the relationship between the probability plots for architectural and grassland categories and the modulation parameters for a layer in the network. It can be seen that the modulation parameters are closely related to the semantic segmentation probability map, and the boundaries of different categories in the modulation parameters are still relatively clear.
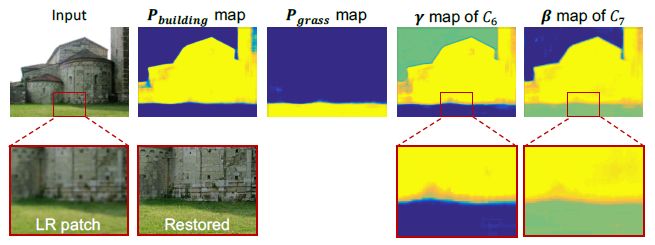
Figure 8:
Relation between Semantic Segmentation Probability Diagram and Feature Modulation Layer Parameters
In actual scenes, the separation limits of object categories are usually not very obvious. For example, in the plant and grass area in Figure 9, the transition between them is “seamless†and continuous, and the semantic segmentation probability map used in this paper is The parameters of the modulation layer also change continuously. Therefore, SFT-GAN can modulate the generation of texture more finely.

Figure 9:
SFT layer can modulate parameters more finely
This article also compares other ways of combining a priori conditions:
Coupling images together with the resulting semantic segmentation probability maps;
Different types of scenes are processed through different branches, and then they are merged using semantic segmentation probability graphs;
Feature modulation method FiLM that does not consider spatial relationships.
From Figure 10 you can see:
The results of method 1) are not valid for the SFT layer (multiple SFT layers in the SFT-GAN model can combine the prior conditions more closely);
The efficiency of method 2) is not high enough (SFT-GAN only requires one forward operation);
Method 3) Since there is no spatial position relationship, textures between different classes interfere with each other.

Figure 10:
Comparison of the results of combining different prior condition
in conclusion
This paper deeply discusses how to use the semantic segmentation probability graph as a semantic priori to constrain the solution space of the super-resolution so that the generated image texture more conforms to the real and natural texture characteristics. A novel spatial feature modulation layer (SFT) has also been proposed to effectively incorporate a priori condition into an existing network. The spatial feature modulation layer can use the same loss function as existing super-resolution networks to train end-to-end. When testing, the entire network can accept images of any size and size as input. Only one forward propagation is required, and high-resolution images combined with semantic class a priori can be output. Experimental results show that compared with the existing super-resolution algorithms, the images generated by the SFT-GAN model in this paper have a more realistic and natural texture.
Usb Data Cable,Charging Data Cable,Usb Data Transfer Cable,Fastest Data Transfer Cable
Guangzhou YISON Electron Technology Co., Limited , https://www.yisonearphone.com