Heart disease has been a major cause of death in the United States in recent decades, so it is not surprising that more and more Americans suffer from heart failure. It is estimated that by 2030, American adults diagnosed with heart failure will increase by 46%, which means that the number of patients will reach 8 million, and about half of them will die within five years after diagnosis. (Heart failure: referred to as heart failure, refers to the failure of the cardiac systolic function and/or diastolic function, can not fully discharge the venous blood out of the heart, resulting in blood deposition in the venous system, insufficient blood perfusion in the arterial system, thus causing cardiac circulatory disorders Syndrome

Heart failure is difficult to diagnose early. With the help of the National Institutes of Health, a team of scientists at IBM Research teamed up with scientists at Sutter Health and clinical experts at Geisinger Health System to use electronic health records. Information that may be hidden behind it, studies and predicts heart failure. In the past three years, using recent advances in AI such as natural language processing, machine learning, and big data analytics, the team trained a model that diagnosed heart failure one to two years earlier than the current typical diagnosis. This study presents important insights on the data required for the training model as well as the actual trade-offs, and develops new application methods that are easier to apply in future models.
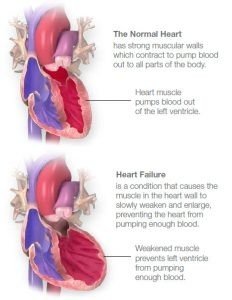
Normal heart and failing heart (Source: American Heart Association)
Today's doctors usually schedule heart failure tests on patients and record their signs and symptoms of heart failure in their medical records. Despite the best efforts that have been made, patients are usually diagnosed with heart failure only after an acute incident has been treated with hospital care, when the disease has caused irreversible progressive organ damage to the body.
The team’s research focuses on detecting and predicting how much risk the patient has of heart failure by using the data contained in the electronic medical records system one year or a few years before the typical clinical diagnosis.
To achieve their goals, applying natural language processing and machine learning methods, the team developed and applied several cognitive computing and AI techniques to analyze patient data in the project.
In the course of the project, the team is committed to achieving a series of goals and has obtained some unexpected discoveries, including:
1. The first objective is to understand the effectiveness of Framingham Heart Failure Signs and Symptoms (FHFSS) for early detection, which is a traditional risk factor that clinicians routinely use to diagnose heart failure. Researchers use natural language processing techniques (NLP) to extract information from unstructured data (such as doctor notes) by parsing information and identifying concepts (including Framingham risk criteria or other types of symptoms). Interestingly, the results of the study showed that of the 28 original FHFSS signs and symptoms, only 6 were confirmed to be reliable predictors of future heart failure.
2. The second goal is to determine whether heart failure can be more accurately predicted by combining unstructured data from doctor's notes with structured electronic medical record data. To do this, the team applied machine learning methods to build a predictive model that considers the combination of variables. The results of the study showed that other types of routine data collected in electronic medical records (such as disease diagnosis, medication prescriptions, and laboratory tests) may be a more useful predictor of heart failure attacks in patients when used in combination with FHFSS.
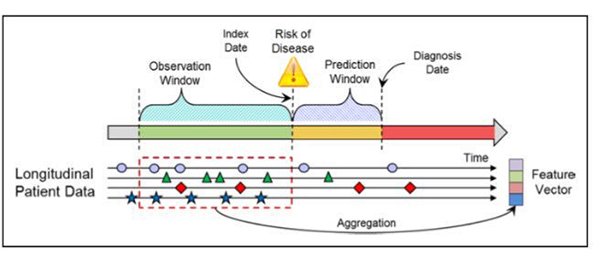
The above shows a model diagram of a heart failure prediction study that can determine heart failure one to two years earlier than current methods. Using longitudinal electronic medical records (EHR), researchers extracted and analyzed various structured and unstructured data types during the observation period, where the index date represents the earliest date that can be predicted, and the prediction window refers to the traditional A time period during which the model can make predictions before the means are diagnosed.
In helping to detect the possibility of heart failure in individuals, the study also allowed the team to gain insights into the trade-offs between specific data types and practicality. For example, when using more diversified data types, the performance of the model is improved, and the combination of diagnosis, medication will, and hospital data is the most important data type. Using knowledge-driven drugs and diagnostic ontology, variables are summarized into higher-level concepts, and data-driven methods are developed to identify and select the most significant variables, creating smaller and more powerful subsets of variables. In the end, the team developed a predictive model with excellent performance and practicality.
This is critical from a clinical point of view because the patient factor used in the model may exceed 1,000, but no healthcare professional wants to enter so many variables. The minimum amount and type of data required to train effective predictive disease models, these research results provide practical guidelines. In November last year, he published a paper ("Early Detection of Heart Failure Using Electronic Health Records") and another paper ("Learning About Machine Learning: The Promise and Pitfalls of Big Data and the Circulation: Cardiovascular Quality and Outcomes". "Electronic Health Record") documents other practical implications of this study.
The above three parties will continue to cooperate to further advance the current research results. The exciting aspect of this work is that it has potential for other diseases. The availability of big data and the combination of innovative cognitive computing are expected to make major advances in clinical diagnosis and early disease detection.
Iget Legend,Iget Legend Pod Pen Kit,4000 Puffs Iget Legend Disposable Vape,Iget Legend E-Cigarette Australia
Shenzhen Uscool Technology Co., Ltd , https://www.uscoolvape.com